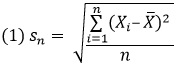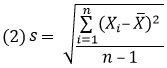Большинство пользователей обратятся к Excel, если нужно построить кольцевую диаграмму. Я тоже в 2012 г. написал на эту тему заметку – Excel. Круговая диаграмма с двумя наборами данных. Однако, около месяца назад я начал читать книгу Нейтана Яу Искусство визуализации в бизнесе. Автор работает в области инфографики, для которой стандартные средства Excel являются недостаточно выразительными. На страницах книги автор знакомит читателей с различными программами, которые расширяют возможности (см., например, Создание столбчатой диаграммы в R).
В настоящей заметке интерактивная кольцевая диаграмма будет построена с помощью программы Protovis. Protovis — бесплатный инструмент для визуализации с открытым исходным кодом. Protovis — это JavaScript-библиотека, позволяющая использовать возможности современных браузеров для работы с масштабируемой векторной графикой. Поскольку графические объекты генерируются динамически, это дает возможность делать их анимированными и интерактивными. А потому Protovis — отличный выбор для создания онлайн-графики. [1]
На рис. 1 показано, к чему вы будете стремиться. Когда указатель мыши оказывается поверх того или иного сектора, вы видите, сколько именно человек проголосовало за данную категорию. Интерактив может быть и более продвинутым, но прежде чем давать волю фантазии, необходимо освоить азы.
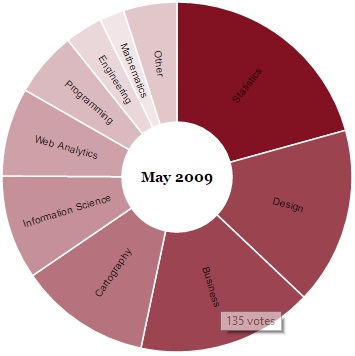
Рис. 1. Интерактивная кольцевая диаграмма, созданная с помощью библиотеки Protovis.js
Подробнее »Интерактивная кольцевая диаграмма, созданная с помощью Protovis