В этой всемирно известной книге автор рассказывает о различных способах злоупотребления статистикой в целях обмана аудитории и манипулирования ее мнением. Каждый день на вас пытаются повлиять, чтобы сподвигнуть на покупку какого-то «нужного» продукта или на выбор «правильного» кандидата: «Благодаря пасте “Чистые зубы” образование кариеса снижается на 23%!»; «Политика N поддерживает 85% граждан»… Как понять, насколько достоверны те или иные данные? Каким образом происходят подсчеты? Что учитывается, а что остается за кадром? Автор раскрывает секретные инструменты статистиков и вооружает читателя знаниями, которые помогут разобраться во всех хитросплетениях этой науки и не позволят ввести в заблуждение. На английском языке книга впервые вышла в 1954 г.
Дарелл Хафф. Как лгать при помощи статистики — М.: Альпина Паблишер, 2015. — 168 с.

Скачать конспект (краткое содержание) в формате Word или pdf
Купить книгу в Ozon, Лабиринте или ЛитРес
Как когда-то говаривал писатель-юморист Генри Фелсен (весьма далекий от медицины), при должном лечении простуда проходит через семь дней, в противном случае она сама собой пройдет через неделю. Точно так же обстоят дела со многим из того, что вы читаете и слышите. Средние величины, зависимости, тенденции и графики не всегда есть то, чем кажутся. Подчас в них таится много больше интересного, чем видно на первый взгляд, а иногда и куда как меньше. Эта книга — своего рода руководство для начинающих, в котором изложены азы применения статистики в целях обмана.
Глава 1. Выборка изначально необъективна
Процедура составления выборки представляет собой сердцевину большей части статистических данных, которые встречаются в самых разнообразных сферах. Если взятая вами для исследования выборка достаточно велика и правильно отобрана, то для большинства надобностей она будет вполне репрезентативной. В противном случае выборка даст вам значительно менее точное представление о целом, чем сколько-нибудь обоснованные прикидки, а ее единственным достоинством будет разве что иллюзорное впечатление научной точности.
Результат выборочного исследования не может быть лучше выборки, на которой оно основано. К тому моменту, когда собранные данные, пройдя сквозь все процедуры статистических манипуляций, сведены к средним показателям, выраженным с точностью до десятых долей, они уже приобретают некий ореол убедительности, от которой не останется и следа, если повнимательнее взглянуть на сам процесс выборочного исследования. Чтобы данные выборочного исследования имели значительную ценность, они должны основываться на репрезентативной выборке, то есть на выборке, из которой устранены все возможные источники предвзятости.
Полезно помнить и о том, что скрытые источники необъективности способны с такой же легкостью подорвать надежность выборки, как и очевидные. Я имею в виду, что, даже если вам не удается обнаружить явный источник необъективности, позвольте себе некоторую долю сомнений и не доверяйте выводам безоговорочно, если имеется хоть какая-то вероятность, что они предвзяты.
Давайте вернемся в 1936 г., к временам, когда влиятельнейший журнал Literary Digest, общепризнанный в то время лидер изучения предпочтений американских избирателей, потерпел приснопамятное фиаско. Те десять миллионов опрошенных телефонных абонентов и подписчиков Literary Digest, которые уверили редакцию злополучного журнала, что победителем в президентской гонки выйдет республиканец Альфред Лэндон с 370 голосами выборщиков против 161 голоса за Франклина Рузвельта, были из того же списка рассылки, каким журнал воспользовался в 1932 г., когда блестяще предсказал итоги президентских выборов.
Разве можно было заподозрить в предвзятости людей из списка, который в прошлом так хорошо себя зарекомендовал? Но, разумеется, предвзятость имела место, и список был нерепрезентативен, что и установили авторы диссертаций и прочие любители изысканий постфактум. Контингент населения, который в 1936 г. мог себе позволить иметь телефон и подписываться на Literary Digest, не был срезом всей совокупности избирателей. В экономическом плане это была особая категория населения, то есть нерепрезентативная выборка, поскольку она изобиловала теми, кто поддерживал Республиканскую партию. Данная выборка и отдала предпочтение Лэндону, тогда как избиратели в массе своей имели другое мнение на этот счет.
Проверить, действительно ли выборка имеет случайный (произвольный) характер, можно с помощью такого вопроса: каждое ли имя или предмет из обследуемой совокупности имеют равный шанс попасть в выборку?
Как представляется, сильнодействующим фактором будет тенденция, которую никогда не следует сбрасывать со счетов, когда знакомишься с результатами социологических опросов: желание респондента угодить интервьюеру.
У нас достаточно оснований сделать предположить, что все социологические опросы в целом грешат предвзятостью. Это крен в сторону людей более состоятельных, более образованных, более информированных и осторожных, с более пристойным внешним видом, общепринятым поведением и с более устоявшимися привычками, чем у того среднестатистического гражданина, представлять которого их выбрали.
Глава 2. Грамотно выбранное среднее
Когда вам рассказывают, что некое число представляет собой среднюю величину, это мало о чем вам скажет, пока вы не разберетесь, какой из трех основных видов среднего перед вами — среднее арифметическое, медиана или мода.
Когда мне требовался показатель побольше, я упомянул $15 000. Это было простое среднее, то есть среднее арифметическое доходов всех семей, проживающих в той местности. Для его расчета требуется сложить доходы всех семей и разделить получившуюся сумму на число семей. Спустя год я воспользовался средним показателем меньшей величины — он представляет собой медиану и означает, что половина семей в рассматриваемой местности имеет годовой доход выше $3500, а вторая половина — ниже $3500. Я мог бы пустить в ход и моду, то есть чаще всего встречающееся значение в числовом ряду, составленном из доходов семей в интересующей нас местности. Если у большей части проживающих там семей годовой доход составляет $5000, это значение и будет модой, или модальным доходом.
Разные виды среднего имеют близкие значения, когда дело касается данных наподобие тех, что относятся ко многим характеристикам человека. Они настолько любезны, что изволят тяготеть к тому, что называется нормальным распределением. Если начертить кривую нормального распределения, то по форме она будет напоминать колокол, а среднее арифметическое значение, медиана и мода попадут в одну и ту же точку.
Но все совсем не так, когда стоит задача описать размер их доходов. Порядка 95% всех показателей будут ниже, чем $10 000, и они займут место в левой части кривой. В итоге вместо симметричной, как колокол, кривой вы получите кривую, скошенную в одну сторону. С одной стороны — крутая горка, с другой — постепенный плавный спуск. Среднее арифметическое окажется на некотором расстоянии от медианы.
Так уж получилось, что большинство ваших соседей — мелкие фермеры, наемные работники в близлежащем поселке или люди, отошедшие от дел и живущие на пенсию. Однако трое — миллионеры, они наведываются в здешние дома только по выходным, и именно за счет их миллионов суммарный годовой доход по вашей округе достигает такой значительной величины (и, соответственно, неимоверно увеличивает средний арифметический доход жителей). Из-за этих троих показатель среднего дохода приобретает огромный размер, какого и близко не имеет почти никто из остальных жителей местности. Это тот самый случай, когда шутка «Практически все имеют доход ниже среднего» становится реальностью (рис. 1).

Рис. 1. Виды среднего значения
Глава 3. Нюансы, о которых скромно умалчивают
«Потребители отмечают, что благодаря зубной пасте компании Doakes у них образуется на 23% меньше кариеса», — гласит набранный аршинными буквами заголовок. Почему компании Doakes так легко удалось, не прибегая к вранью, добиться широкого освещения в прессе, да еще и подкрепить все это заключениями независимых экспертов. Предположим, некая немногочисленная группа потребителей в течение полугода ведет учет состояния своих зубов, а потом переключается на пасту от Doakes. Далее можно ожидать одного из трех вариантов: кариеса станет больше, кариеса станет ощутимо меньше или никаких изменений не последует. Если события пойдут по первому или последнему варианту, производитель пасты просто зафиксирует эти показатели (где-нибудь у себя, вдали от глаз общественности) и предпримет новые попытки. Рано или поздно в дело вмешается случай, и у испытуемых зафиксируют-таки значительное улучшение, достойное газетных заголовков, а то и целой рекламной кампании. И случится это независимо от того, пользуются ли испытуемые пастой Doakes, питьевой содой или своим привычным средством по уходу за зубами.
Малочисленную группу испытуемых важно задействовать вот почему: при многочисленной группе любой случайный сдвиг в лучшую сторону будет, скорее всего, довольно скромным и потому не заслужит упоминания в прессе. Только при достаточно большом количестве попыток закон средних чисел позволяет получить значимую характеристику или прогноз.
Должен ли каждый из нас стать сам себе статистиком и лично изучать исходные данные любого исследования? В принципе, все не так уж плохо, тем более что есть такая штука, как критерий значимости, суть которого несложно понять. Это просто способ показать, насколько вероятно, что полученная в ходе испытаний цифра отражает реальный результат, а не что-то случайное. Это тот самый нюанс, о котором обычно умалчивают. Степень значимости проще всего выразить в виде вероятности, как это делает Бюро переписи населения.
Есть еще одного сорта нюанс, который предпочитают не указывать, но его отсутствие способно не меньше дискредитировать заявленные данные. Речь идет о размахе исследуемого признака или диапазоне отклонения от указанного среднего. Часто бывает, что среднее представляет собой такое чрезмерное упрощение, что оно даже хуже, чем бесполезно.
Сходным образом мелкие опущенные детали в труде под названием «Нормы развития Гезелла» ввергли в панику папочек и мамочек. Дай только родителю прочитать раздел, где говорится, что в возрасте стольких-то месяцев ребенку уже полагается сидеть, и он сейчас же примерит это к собственному малышу. А поскольку примерно половина детей к указанному возрасту все еще не научилась сидеть, это сделало несчастными многих и многих родителей. Этого недоразумения во многом удалось бы избежать, если бы наряду с показателем «нормы» или среднего значения был бы указан диапазон этой самой нормы. Тогда родители увидели бы, что их дети попадают в пределы нормы и прекратили бы беспокоиться по поводу мелких и ничего не значащих отклонений.
Не доверяйте показателям, графикам и тенденциям, когда вам предъявляют их без тех важных цифр, что могли бы прояснить смысл (рис. 2).
Рис. 2. «Слепой» график
Глава 4. Много шума практически из ничего
Питер и Линда недавно прошли тест на уровень умственного развития. В наши дни из всякого рода тестов на умственные способности сотворили прямо-таки фетиш и разводят вокруг них шаманские пляски. Вы выяснили, что у Питера коэффициент умственного развития (IQ) составил 98, а у Линды — 101. А вам, разумеется, известно, что в тесте на IQ коэффициент 100 принят за средний, то есть нормальный уровень. Ага. Линда у нас одареннее Питера. Это означает, что ее умственное развитие выше среднего. А у Питера — ниже среднего, но не будем придавать этому особого значения.
То, насколько точной может считаться ваша выборка, призванная дать представление обо всей совокупности, есть мера, которую можно выразить количественно: это вероятная ошибка и стандартная ошибка. Вероятная ошибка теста на IQ определяется как 3%. Это ни в коей мере не говорит о том, насколько в основе своей хорош данный тест, а просто указывает, с какой надежностью он измеряет то, что призван измерять. Итак, определенный у Питера IQ можно было бы полнее выразить в виде 98±3, а коэффициент IQ Линды — в виде 101±3. Это означает, что у IQ Питера равные шансы оказаться где-то в диапазоне от 95 до 101. Аналогично и у Линды вероятность попасть в интервал от 98 до 104 ничуть не лучше, чем пятьдесят на пятьдесят.
Все сказанное подводит нас к тому выводу, что единственно правильным будет рассматривать IQ и результаты многих других выборочных исследований не сами по себе, а с учетом размаха отклонений. Тогда «нормальным» будет считаться показатель не 100 пунктов, а в пределах, скажем, от 90 до 110. Проводить сравнения между цифрами, имеющими маленькую разницу, бессмысленно. Вам следует постоянно помнить об этом плюсе или минусе, то есть ошибке в ту или другую сторону, даже (или особенно) если ее пределы не указаны. Те, кто пренебрегает ошибкой, которая изначально присуща любым исследованиям на основе выборки, рискуют совершить поразительно глупые поступки.
Журнал Reader’s Digest опубликовал на своих страницах результаты исследований, показывающие, сколько никотина и всякого прочего содержится в дыме сигарет разных марок. Вывод, который сделал журнал и который явно следовал из подробно расписанных результатов, состоял в том, что все марки сигарет практически одинаковы по содержанию вредных веществ и потому не имеет никакого значения, сигареты какой марки вы курите.
Но нашелся кое-кто, чей зоркий глаз заприметил кое-что интересное. В перечнях содержания вредных веществ, почти одинаковых для всех сигаретных марок, какая-то одна волей- неволей должна была оказаться в самом конце, и этой маркой была Old Gold. Вот оно! На страницах всех газет разом появились рекламные объявления, что из всех марок сигарет, протестированных не кем-нибудь, а крупнейшим общенациональным журналом Reader’s Digest, дым сигарет Old Gold содержит меньше всего вредных веществ. При этом в рекламе отсутствовали какие бы то ни было цифры или хотя бы намеки, что разница между марками сигарет ничтожна.
Глава 5. График – лучше не бывает
Пожалуй, простейшей разновидностью статистической картинки или графика будут всевозможные кривые. Они весьма полезны, когда нужно продемонстрировать те или иные тенденции.
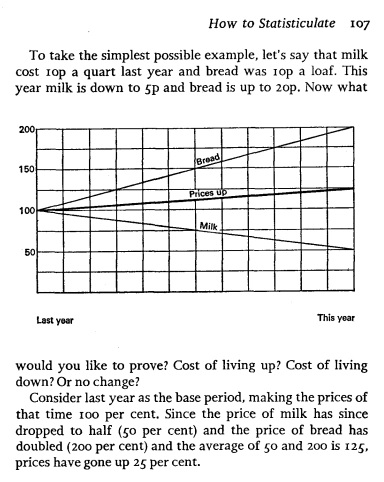
Сейчас мы сделаем так, что наш график наглядно покажет, как национальный доход США ежегодно увеличивается на 10% (рис. 3).
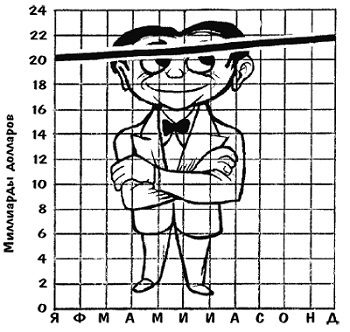
Рис. 3. «Честный» график, на котором цифры (10%-ный рост) и визуальный ряд совпадают
Всякий сможет посмотреть и сразу понять, что к чему, поскольку график выполнен с соблюдением пропорций и внизу для сравнения имеется линия нулевой отметки. Ваши 10% выглядят именно как 10% — как восходящая тенденция, существенная, хотя и не сказать, чтобы такая уж впечатляющая.
Этого вполне достаточно, если ваша задача только в том, чтобы передать информацию. А давайте предположим, что вы хотите одержать верх в споре, потрясти читателей, побудить их к действию или что-то им продать. Но для этого вашему графику не хватает забористости, как-то он не впечатляет. А вы возьмите, да и отрежьте нижнюю часть (рис. 4).

Рис. 4. Отсутствие точки отсчета (нуля ординат) делает рост более впечатляющим
Ну вот, уже лучше.
Есть один хитрый трюк, который придаст вашему скромному десятипроцентному росту такой шикарный вид, какой не полагается и стопроцентному. Просто измените пропорции между осью ординат и осью абсцисс (рис. 5).
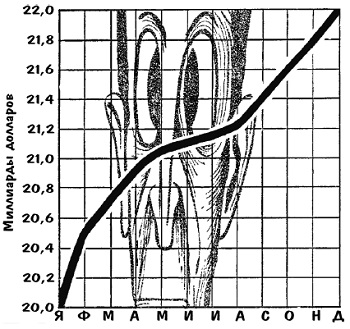
Рис. 5. Изменение масштаба по оси ординат делает 10%-ный рост впечатляющим
Глава 6. Схематичная картинка
Наглядной подачей информации называют графики или диаграммы, на которых фигурка человечка изображает миллион человек. Она помещается рядом с кучей денег на тысячу или миллиард долларов, или контурным рисунком бычка, показывающим, сколько говядины вы потребите в следующем году. Это вещь полезная. И, боюсь, она радует глаз. Но наглядная графика способна стать красноречивым, нечистым на руку и не знающим поражений лжецом (сейчас используют термин инфографика).
Породила наглядную графику, или пиктограмму, обычная столбиковая диаграмма. Столбиковая диаграмма тоже умеет врать. Убедиться в этом легко. Достаточно повнимательнее взглянуть на любой образец такой диаграммы, где столбики увеличиваются и в ширину, и в высоту, хотя и отображают одномерный фактор, или, когда изображаются трехмерные объекты, объемы которых трудно с ходу сопоставить.
Предположим, мне понадобилось бы показать, как соотносятся две величины — средний недельный заработок плотников в США и в какой-нибудь, скажем, Ротундии. Цифры эти могли бы составлять $60 и $30 соответственно. А вот и моя гистограмма: по вертикальной оси отложена величина недельного заработка в долларах. Картина ясная и правдиво показывает положение дел. Столбик на диаграмме, отображающий вдвое большую сумму, вдвое больше по размеру, таковым он и выглядит (рис. 6).
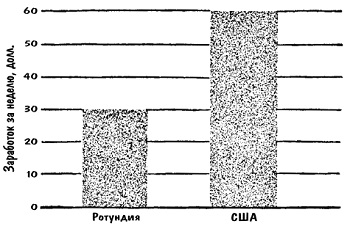
Рис. 6. Столбиковая диаграмма (гистограмма) «честно» отражает 2-кратное превосходство
Вместо столбиков можно использовать другой графический объект, который лучше всего ассоциируется со звонкой монетой — мешки с деньгами. Рисунок по-прежнему будет правдив и ясен, а беглый взгляд на него никого не введет в заблуждение. Таким способом и создаются честные пиктограммы (рис. 7).

Рис. 7. Честная пиктограмма: мешки одинаковые, но для США их в два раза больше
По правде говоря, я хочу навести вас на определенную мысль, создать у вас преувеличенное впечатление от моих данных, но при этом мне вовсе не хочется, чтобы меня уличили в подтасовке. А делается это так: сначала я нарисую мешок денег, изображающий тридцатидолларовый недельный заработок плотника в Ротундии, а затем нарисую второй мешок, размерами вдвое больше, и он будет изображать $60, которые зарабатывает за неделю американский плотник (рис. 8). Пропорция соблюдена, не правда ли? Такая диаграмма создает как раз то впечатление, к которому я стремился. Рядом с внушительным мешком денег, которые зарабатывает американский плотник, заработок иностранца выглядит особенно ничтожным и жалким. В этом, разумеется, и состоит подвох. Второй мешок в два раза выше первого, он еще и в два раза шире. И на бумаге он занимает не вдвое, а вчетверо больше места.

Рис. 8. «Нечестная» пиктограмма: мешок в два раза выше и в два раза шире, т.е. в четыре раза больше
Глава 7. Псевдообоснованная цифра
Привязать цифру, отражающую какой-то факт, к другому факту — прием известный и всегда сослужит вам добрую службу. Допустим, вы не можете доказать, что ваше замечательное лекарство излечивает от простуды, но никто не мешает вам напечатать (крупным шрифтом) результаты настоящего лабораторного исследования: полкапли лекарства, помещенные в пробирку, через 11 секунд уничтожают 31 108 бактерий. Не уточняйте бактерии какого рода пали жертвой вашего средства. Кто ж его знает, какие бактерии вызывают простуду, особенно если возбудители простуды — вовсе не бактерии?
Изучая статистику аварий, вы можете запугать себя до смерти относительно любого вида транспорта… если не сообразите, насколько некорректно привязаны приводимые цифры к явлениям, которые они призваны характеризовать. В 1953 г. в авиакатастрофах погибло больше людей, чем в 1910 г. Должен ли отсюда следовать вывод, что авиаперелеты стали более опасны? Чепуха. Просто люди стали летать в сотни раз больше, чем раньше, вот и всё.
Определить степень вероятного риска позволят данные о количестве смертельных жертв на миллион пассажиро-миль по каждому из виду транспорта. Эти показатели точнее других подскажут вам, на каком виде транспорта вы больше всего рискуете жизнью.
В качестве начальника отдела кадров компании, у которой возникли трения с профсоюзом, вы «проводите опрос» сотрудников, чтобы выяснить, у скольких из них имеются жалобы на профсоюз. Если только сам профсоюз не есть сборище ангелов, можете спокойно задавать свой вопрос и честно записывать ответы, а потом представить это за доказательство, что у большинства сотрудников действительно есть какие-то жалобы. На основе собранных данных вы составляете доклад, где говорится, что «подавляющее большинство (78%) сотрудников настроены против профсоюза». По сути вы сделали вот что: собрали в одну кучу все без разбора жалобы и мелкие конфликты, а затем выдали их за нечто другое, что выглядит примерно так же. Со своей стороны, профсоюз может с такой же легкостью «доказать», что практически все сотрудники возражают против порядка управления компанией.
Любую количественную величину несложно выразить множеством разнообразных способов. Вы можете, например, представить один и тот же факт, называя его доходностью продаж в 1%, рентабельностью инвестиций в 15%, десятимиллионной прибылью, ростом прибылей на 40% (по сравнению со средним показателем за 1935–1939 гг.) или сокращением на 60% по сравнению с предыдущим годом. Суть в том, чтобы выбрать формулировку, которая лучше всего подходит для текущих надобностей. А после остается уповать на то, что лишь единицы, читая эту информацию, сообразят, насколько она искажает реальное положение дел.
Уровень смертности в военно-морском флоте США в период Испано-Американской войны 1898 г. составлял девять человек на тысячу. За тот же период уровень смертности среди гражданского населения Нью-Йорка достигал шестнадцати человек на тысячу. Позже эти цифры использовали вербовщики, чтобы показать: служить в ВМС безопаснее, чем находиться за его пределами. Допустим, что сами эти цифры точны (вероятно, так оно и есть). Давайте остановимся на мгновение и проверим, сообразите ли вы, что лишает практически всякого смысла сами эти цифры, или хотя бы заключение, которое выводили из них вербовщики.
Все дело в том, что группы, к которым относятся вышеуказанные цифры, несопоставимы. В рядах ВМС служат главным образом молодые мужчины, признанные здоровыми. Гражданское же население состоит среди прочего из малых детей, стариков и больных, и для этих категорий населения уровень смертности выше, где бы они ни находились.
Картинки «было — стало» представляют собой знакомый всем нам по журнальным статьям и рекламе трюк. Например, пара картинок показывает вам, что бывает, когда юная особа начинает применять ополаскиватель для волос. И — бог ты мой! — ее шевелюра действительно выглядит значительно лучше после, чем до. Но при внимательном изучении вы замечаете, что перемен добились главным образом за счет того, что девушку заставили улыбнуться, а ее волосы сзади подсвечены ярким светом. Тут скорее следует отдать должное мастерству фотографа, чем чудодейственной силе ополаскивателя (рис. 9).

Рис. 9. До и после
Глава 8. И снова это «после — значит вследствие»
Существует одно заблуждение, древнее как мир: если событие В следует за событием А, значит, событие А является причиной события В. Однако, из корреляции между А и В не следует, ни того, что А причина В, ни, наоборот, того, что В причина А. Представляется куда более вероятным, что ни одно из этих двух явлений не обусловливает другого. Скорее оба они следствие какого-то третьего фактора.
Существует корреляция, обусловленная случайными причинами. Возможно, у вас получилось установить корреляцию между двумя рядами чисел, чтобы доказать некое маловероятное утверждение. Но если вы снова попробуете проделать расчет, но уже на других цифрах, никакого доказательства не получится. Вспомните историю про зубную пасту из главы 3.
Другой случай — взаимосвязь действительно существует, но нельзя сказать, какая из переменных выступает причиной, а какая следствием. Имейте в виду, что корреляция действительно может существовать и притом основываться на реальной причинно-следственной связи — и тем не менее не представлять почти никакой пользы, когда надо определиться с действиями в каком-нибудь конкретном случае.
Столкнувшись с корреляцией, убедитесь прежде всего, не того ли она сорта, что образуется под влиянием самого течения событий или стародавних веяний моды. В наши дни легче легкого продемонстрировать положительную корреляцию между любой парой явлений вроде следующих: количество студентов в университетах, число пациентов в психиатрических больницах, потребление сигарет, частота сердечных заболеваний, использование рентгеновских аппаратов, производство искусственных зубов, зарплаты учителей в Калифорнии, прибыли в игорных домах Невады. Назвать один пункт из этого списка причиной другого пункта будет откровенной глупостью. И тем не менее такое происходит каждый божий день.
Глава 9. Как производить статистикуляции
Когда публику вводят в заблуждение при помощи статистических материалов, это можно назвать статистическими манипуляциями, а если в одно слово (пускай оно и немного неуклюжее), то статистикуляциями.
Проценты предлагают благодатную почву для введения в заблуждение. И подобно цифрам с неизменно впечатляющими десятыми долями, проценты способны придавать вид точности цифрам далеко не точным. В издаваемом Министерством труда США журнале Monthly Labor Review однажды написали, что на территории Вашингтона в таком-то месяце среди всех предложений по частичной занятости в домашнем хозяйстве (с оплачиваемым проездом к месту работы на общественном транспорте) в 4,9% случаев предлагается оплата $18 в неделю. Как позже выяснилось, указанные проценты были выведены на основе каких-то двух предложений, а в общей сложности таковых было всего-то 41. Выраженный в процентах показатель, если он рассчитан на основе ограниченного числа случаев, скорее всего, искажает реальную картину. Будет полезнее и информативнее привести сами показатели. А уж когда проценты вычисляются и потом подаются с точностью до десятых, знайте, что вы делаете шаг на пути от глупости к жульничеству.
А посмотрите на идею, будто проценты можно складывать с такой же легкостью, как яблоки в корзинку. Взгляните только, как убедительно выглядит пример подобного трюка на страницах еженедельного книжного обозрения The New York Times Book Review: «Разрыв между растущими ценами на книги и авторскими заработками, как выясняется, обусловлен существенным ростом производственных и материальных затрат. Вот по статьям: одни только редакционные и производственные затраты за последние десять лет ощутимо выросли — на 10-12%; расходы на материалы возросли на 6-9%, торговые издержки и расходы на рекламу поднялись на 10%. В общей сложности рост затрат достиг как минимум 33% (для крупного издательского дома) и почти 40% для ряда издательств меньшего размера». Но если каждая из статей, из которых складывается себестоимость данной книги, увеличится примерно на 10%, общие затраты на книгу должны, по идее, возрасти примерно на те же 10%.
Это несколько смахивает на байку про хозяина придорожной харчевни, которого попросили объяснить, как ему удается так дешево продавать сэндвичи с крольчатиной. «Очень просто, — отвечал тот. — Мне приходится добавлять некоторое количество конины. Но я смешиваю их поровну: одна лошадь и один кролик».
Глава 10. Как поставить статистика на место
Как смело глядеть в глаза фиктивной статистике и изобличать ее и, что не менее важно, как распознавать добросовестные и полезные данные в непролазных чащобах обмана и фальсификаций, описанию которых главным образом и посвящены предыдущие главы? Предлагаю вам прощупать подозрительные данные с помощью пяти простеньких вопросов.
Кто это говорит? Первое, на что следует обратить внимание, — это предвзятость статданных. Не заинтересован ли говорящий? Нет ли сознательного искажения сведений? Иногда намеренно подменяют точку отсчета. Для одного сравнения за основу берется какой-то один год, а для другого сравнения — другой год, более подходящий. Когда упоминается «какое-надо-имя», удостоверьтесь, что авторитет его обладателя действительно стоит за данной информацией, а не просто приплетается ради пущей убедительности.
Откуда ему это известно? Приглядывайтесь, нет ли свидетельств тому, что выборка смещенная, то есть отобрана ненадлежащим образом или сформировалась сама собой (т.е., из заинтересованных лиц). Достаточно ли велика выборка, чтобы на ее основе сделать сколько-нибудь надежный вывод?
Чего не хватает? Далеко не всегда сообщают, сколько случаев было взято для изучения. Отсутствия такой цифры достаточно, чтобы бросить тень подозрения на все сообщение в целом. Будьте начеку, если вам называют среднее без уточнения его вида, во всех случаях, когда можно заподозрить, что среднее арифметическое и медиана существенно различаются. При сообщении, что такой-то параметр показал динамику 25%, неплохо поинтересоваться, а какая вариабельность свойственна ему в другое время?
Бывает и так, что в источнике приводятся проценты, а стоящие за ними исходные цифры отсутствуют, и это тоже способно ввести в заблуждение. Давным-давно, когда Университет Джонса Хопкинса только начал принимать девушек, некто, не испытывавший особых восторгов по поводу совместного обучения, обнародовал данные, ставшие для многих потрясением: оказывается, 33,3% студенток университета повыходили замуж за преподавателей! Однако исходные цифры позволяли точнее оценить картину «бедствия». На тот момент в списке учащихся числились три девушки-студентки, и одна из них действительно вышла замуж за преподавателя.
Не подменен ли объект исследования? Не произошло ли подмены в процессе перехода от исходных данных к выводам. Например, рост зарегистрированных случаев заболевания — не всегда то же самое, что рост самих случаев заболевания.
Порой возникают и настоящие нелепости, если цифры основываются на том, что говорят сами люди, — даже когда речь идет об объективных вроде бы фактах. Так, перепись населения выявила большее количество людей в возрасте, скажем, 35 лет, чем тех, кому 34 и 36. В подобных случаях картина искажается оттого, что кто-то из членов семьи, сообщая о возрасте домочадцев и не будучи в нем точно уверенным, часто следует привычке округлять года до величины, кратной пяти. Один из способов обойти подобные ошибки — просить, чтобы респонденты называли не возраст, а дату рождения.
Иногда, чтобы подменить объект интереса, практикуют семантический подход. Вот пример подобного со страниц журнала BusinessWeek: «Бухгалтеры пришли к выводу, что слово «излишки» выглядит отвратительно. Они предлагают исключить его из балансовых отчетов корпораций. Комитет по учетным процедурам Американского института бухгалтеров советует: «…используйте описательные термины, такие как “нераспределенная прибыль” или “удорожание основных средств”».
Есть ли в этом смысл? Такой вопрос почти всегда поставит на место много возомнившего о себе статистика, если все его маловразумительные построения основаны на недоказанном исходном допущении. Возможно, вам приходилось слышать о формуле удобочитаемости Рудольфа Флеша. Считается, что она позволяет измерить, насколько легок для прочтения изложенный прозой текст, при помощи таких простых и объективных параметров, как длина слов и предложений. Эта идея весьма привлекательна, как и прочие подобные ухищрения, придуманные для того, чтобы свести нечто трудноуловимое к цифрам и подменить суждения чистой арифметикой. Формула Флеша строится на допущении, что такие параметры, как длина слов, и определяют удобочитаемость текста. Это допущение, если уж вредничать по полной программе, пока еще только ожидает доказательств (подробнее см. Проверка удобочитаемости текстов по Флешу в Word).
Убедительность точных цифр — еще один фактор, порой вступающий в противоречие со здравым смыслом. Согласно исследованию, о котором писали нью-йоркские газеты, работающей женщине, проживающей со своей семьей, еженедельно требуется $40,13. Любой, у кого при чтении газет не атрофируется здравый смысл, способен сообразить, что расходы на поддержание души в теле невозможно рассчитать с точностью до последнего цента. И все равно трудно устоять перед чертовским соблазном уверовать в эту цифру, ведь сама точность этих $40,13 намекает на солидную осведомленность источника и внушает больше уважения, чем формулировка «около $40».
См. также Левин. Статистика для менеджеров с использованием Microsoft Excel, Идеи Байеса для менеджеров, Как с помощью диаграммы приукрасить действительность? или о факторе лжи Эдварда Тафти.
Удивительно, насколько актуальна книга 1954 года. Надо будет прочесть ее целиком.
Я расстроилась, когда нашла ошибки в примере про изменение цен (молоко и хлеб) в главе 9…
Я нашел в сети оригинал на английском языке. Пример про хлеб и молоко использует иные числа и не содержит ошибки.
Спасибо, что нашли оригинал!
Я думала, что, может, дело в переводе. Один момент в исходных данных там двояко можно прочесть) хотя там есть картинка с числами! Я только сейчас заметила)а она соответствует действительности.
И в переводе вызвало путаницу у меня, фраза «рост на 200%».
Но у меня остаётся вопрос: разве корректно считать среднее от процентов?
Буду очень признательна, если объясните, в чем я ошибаюсь)
Конечно, считать среднее от процентов не корректно. Это и высмеивает автор.
Подскажите, а расчёт по средней геометрической тоже неверен? Я где-то читала, что для процентов этот вид средней как раз применим. И какой бы год мы не взяли за базу, получается одинаковое значение =100%. С другой стороны, мы в текущем году потратим 20 рублей, покупая хлеб и молоко, это меньше, чем в прошлом, где потратили бы 25 рублей. Значит, все-таки средняя стоимость жизни не может быть без изменений?
Подскажите, пожалуйста, в итоге какой правильный расчёт? Вроде, такая простая математика, а я не понимаю, даже стыдно)
>Подскажите, а расчёт по средней геометрической тоже неверен? Я где-то читала, что для процентов этот вид средней как раз применим. И какой бы год мы не взяли за базу, получается одинаковое значение =100%.
Екатерина, применение той или иной арифметики — это не дилемма «можно/нельзя». В каждом случае нужно смотреть, что вы вычисляете, и какие формулы будут адекватны.
>С другой стороны, мы в текущем году потратим 20 рублей, покупая хлеб и молоко, это меньше, чем в прошлом, где потратили бы 25 рублей. Значит, все-таки средняя стоимость жизни не может быть без изменений?
Здесь тоже нельзя просто суммировать)) Ведь объем потребления разных продуктов различается. Есть целая отрасль, которая изучает потребительские индексы. Простого ответа на ваш вопрос не существует…