Как запустить второй экземпляр Excel
В последнее время я извлекаю большие объемы данных с использованием Power Query (PQ). Когда запущен PQ, работать в файлах Excel нельзя. Поэтому передо мной встала задача – запустить второй экземпляр Excel.exe, чтобы пока выполняется длительная процедура в PQ я мог бы работать с другими файлами Excel. Подробнее о плюсах и минусах работы с двумя экземплярами Excel см. Что такое экземпляры Excel и почему это важно?
Любопытно, что часто встречаемая рекомендация Microsoft…
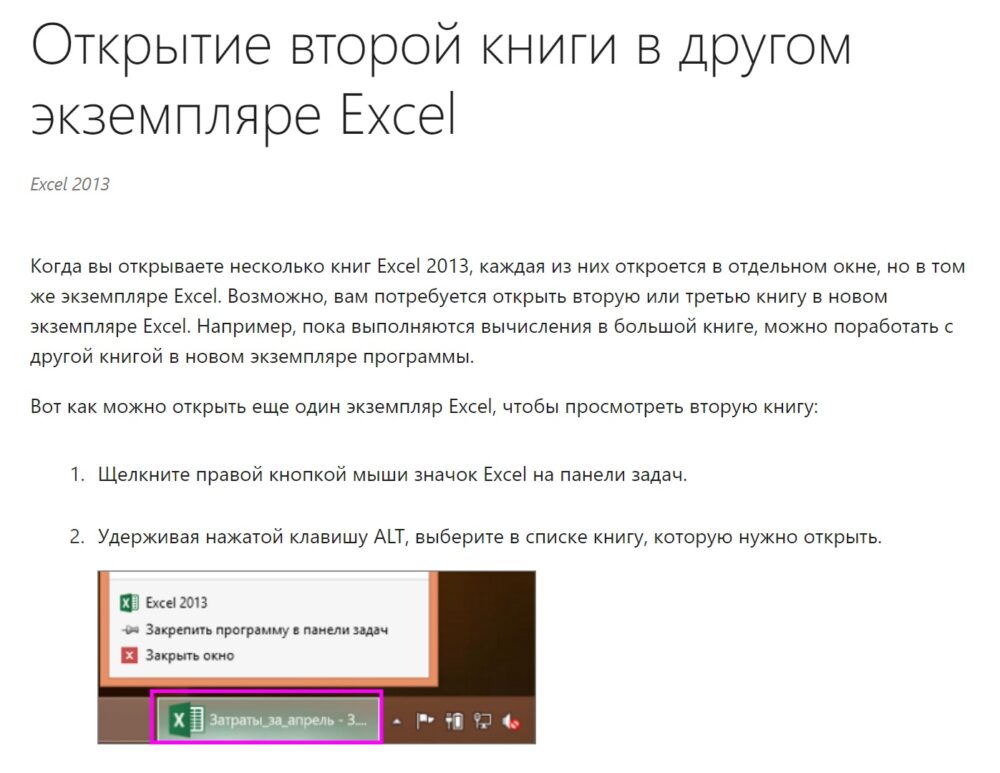
… не работает. Может быть, это связано с тем, что рекомендация дана для Excel 2013, а у меня Excel 365…