Это глава из книги: Майкл Гирвин. Ctrl+Shift+Enter. Освоение формул массива в Excel.
Предыдущая глава Оглавление Следующая глава
Эта заметка для тех, кого по-настоящему интересуют сложных формулы массива. Если вам просто нужно один раз извлечь список уникальных значений, гораздо проще использовать Расширенный фильтр или сводную таблицу. Основные преимущества использования формул – автоматическое обновление при изменении/добавлении исходных данных или критериев отбора. Перед прочтением желательно освежить в памяти идеи, содержащиеся в предыдущих материалах:
- Булева логика: критерии И, ИЛИ (глава 11);
- Динамические диапазоны на основе функций ИНДЕКС и СМЕЩ (глава 13);
- Извлечение данных на основе критериев (глава 15);
- Формулы счета уникальных значений (глава 17).
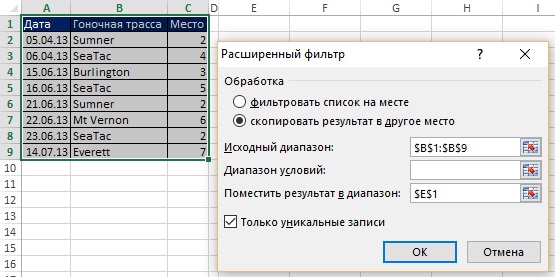
Рис. 19.1. Извлечение уникальных записей с помощью опции Расширенный фильтр
Скачать заметку в формате Word или pdf, примеры в формате Excel
Извлечение уникального списка из одного столбца с помощью опции Расширенный фильтр
На рис. 19.1 показан набор данных (диапазон А1:С9). Ваша цель – получить список уникальных гоночных трасс. Так как вам нужно сохранить исходные данные, вы не можете использовать опцию Удалить дубликаты (меню ДАННЫЕ –> Работа с данными –> Удалить дубликаты). Но вы можете использовать Расширенный фильтр. Чтобы открыть диалоговое окно Расширенный фильтр, пройдите по меню ДАННЫЕ –> Сортировка и фильтр –> Дополнительно, или нажмите и удерживайте клавишу Alt, а затем последовательно нажмите Ы, Л (для Excel 2007 или позже).
В открывшемся диалоговом окне Расширенный фильтр (рис. 19.1) задайте опцию скопировать результат в другое место, проверьте флажок Только уникальные записи, задайте область, из которой будут извлекаться уникальные значения ($B$1:$B$9), и первую ячейку, куда извлеченные данные будут помещены ($E$1). На рис. 19.2 показан, полученный уникальный список (диапазон Е1:Е6). Если вы не включите имя поля в Исходный диапазон диалогового окна Расширенный фильтр (вместо того, что на рис. 19.1 укажите $B$2:$B$9), Excel будет рассматривать первую строку диапазона, как имя поля, и вы рискуете получить дубль. На рис. 19.3 показано одно из многих возможных применений уникального списка.
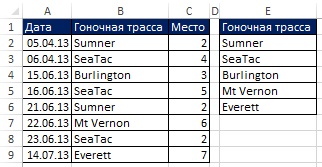
Рис. 19.2. Excel выводит имя поля в ячейку Е1 и уникальный список в ячейки ниже
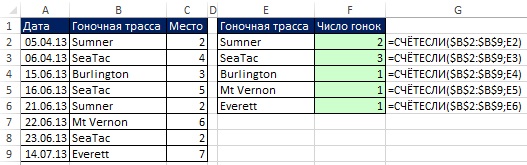
Рис. 19.3. Уникальный список может стать критерием в формулах
Извлечение уникального списка на основе критерия с помощью опции Расширенный фильтр
В последнем примере вы извлекли уникальный список из одного столбца. Расширенный фильтр может также извлекать уникальный набор записей (т.е., строки исходной таблицы целиком) с применением критерия. На рис. 19.4 и 19.5 показана ситуация, в которой нужно извлечь уникальные записи из диапазона А1:D10, для которых имя компании равно АВС. Далее в этой главе вы увидите, как выполнить эту работу с помощью формулы. Однако, если вам не нужно, чтобы процесс был автоматическим, вы можете использовать Расширенный фильтр, что, безусловно, проще формулы.
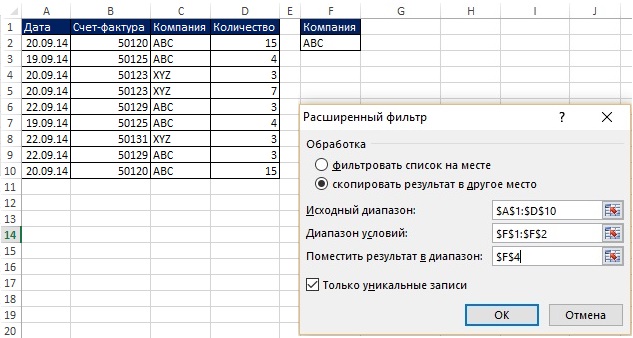
Рис. 19.4. Вам нужны уникальные записи для компании ABC; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
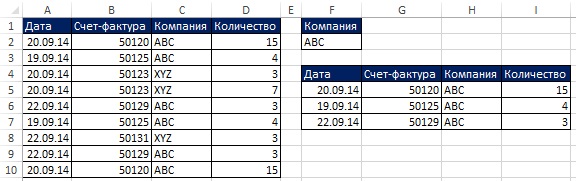
Рис. 19.5. Использование Расширенного фильтра для извлечения уникальных записей на основе критериев гораздо проще, чем метод формул. Однако, извлеченные записи не будут автоматически обновляться, если критерии или исходные данные изменятся
Извлечение уникального списка из одного столбца с помощью сводной таблицы
Если вы уже используете сводные таблицы, то знаете, что каждый раз, когда вы помещаете какое-либо поле в область Строки или Колонны (рис. 19.6), вы автоматически получите уникальный список. На рис. 19.6 показано, как можно быстро создать уникальный список гоночных трасс, а затем подсчитать количество посещений каждой из них. Хотя сводная таблица удобна для извлечения уникального списка из одного столбца, она вряд ли вам пригодится для извлечения уникальных записей на основе критериев.
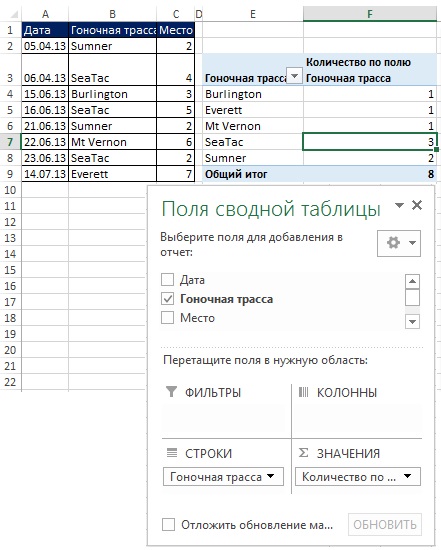
Рис. 19.6. Можно воспользоваться сводной таблицей, когда вам нужен уникальный список и последующий расчет на его основе
Извлечение уникального списка из одного столбца с помощью формул и вспомогательного столбца
Использование вспомогательного столбца упрощает извлечение уникальных данных по сравнению с применением формул массива (рис. 19.7). Этот пример использует методы, с которыми вы познакомились в главе 17 (использование функции СЧЁТЕСЛИ) и главе 15 (использование вспомогательного столбца). Если теперь вы измените исходные данные в диапазоне В2:В9, формулы автоматически отразят эти изменения в области D15:D21.
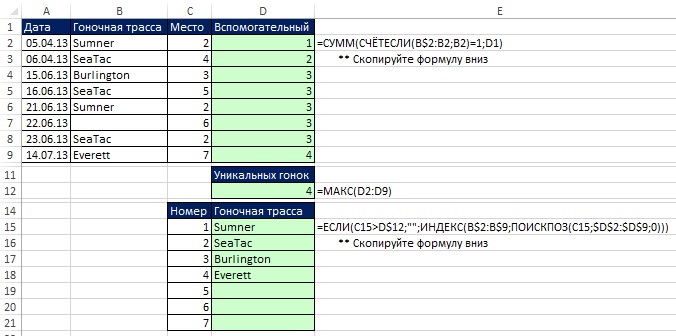
Рис. 19.7. Вспомогательный столбец и формула на основе функции ИНДЕКС для извлечения уникального списка
Формула массива: извлечение уникального списка из одного столбца, используя функцию НАИМЕНЬШИЙ
Поскольку формулы массива, используемые в этом разделе, весьма сложны для восприятия, их создание разбито на этапы: первый – фрагмент, подсчитывающий уникальные значения (глава 17); второй – извлечение данных на основе критериев (глава 15). На рис. 19.8 показана формула расчета уникальных значений (поскольку, это формула массива, она вводится нажатием Ctrl+Shift+Enter). Обратите внимание на следующие аспекты этой формулы:
- Функция ЧАСТОТА возвращает массив чисел (рис. 19.9): для первого появления гоночной трассы возвращается число ее вхождений в исходные данные; для каждого последующего появления гоночной трассы, возвращается ноль (см. свойства функции ЧАСТОТА). Например, Sumner появляется в первой и пятой позициях массива. В первой позиции функция ЧАСТОТА возвращает 2 – общее число Summer в диапазоне В2:В9, в пятой позиции – 0.
- Функция ЧАСТОТА размещена в аргументе лог_выражение функции ЕСЛИ, поэтому функция ЕСЛИ возвращает ИСТИНА для любого ненулевого значения, и ЛОЖЬ – для нулевого.
- Аргумент значение_если_истина функции ЕСЛИ содержит 1, таким образом, функция СУММ подсчитывает число таких единиц.
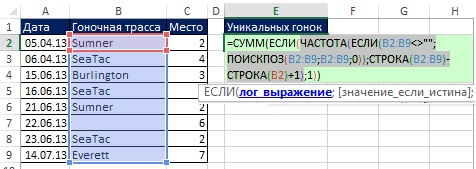
Рис. 19.8. Функция ЧАСТОТА размещена в аргументе лог_выражение функции ЕСЛИ
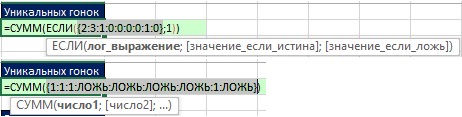
Рис. 19.9. (1) функция ЧАСТОТА возвращает массив чисел; (2) функция ЕСЛИ возвращает 1 для чисел отличных от нуля, и значение ЛОЖЬ для нулей
Теперь создадим формулу извлечения уникального списка. На рис. 19.10 показан массив относительных позиций, размещенный в аргументе массив функции НАИМЕНЬШИЙ.
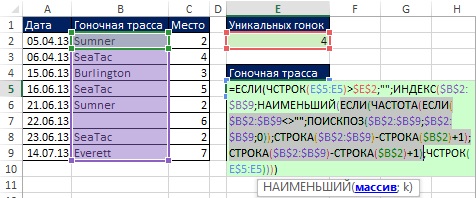
Рис. 19.10. Массив относительных позиций уникальных значений
В предыдущем примере (рис. 19. 9) в аргументе значение_если_истина функции ЕСЛИ размещалась единица, поэтому функция ЕСЛИ возвращала единицы и ЛОЖЬ. Здесь же (рис. 19.10) аргумент значение_если_истина содержит: СТРОКА($B$2:$B$9)-СТРОКА($B$2)+1. Поэтому функция ЕСЛИ (внутри функции НАИМЕНЬШИЙ) возвращает относительный номер позиции в диапазоне с уникальной гоночной трассой или значение ЛОЖЬ для дублей (рис. 19.11).
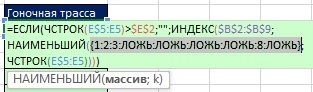
Рис. 19.11. Функция ЕСЛИ возвращает относительный номер позиции в диапазоне с уникальной гоночной трассой или значение ЛОЖЬ для дублей
На рис. 19.12 показать результаты работы формулы. На рис. 19.13 видно, что, как только изменились исходные данные, формулы тут же отразили эти изменения. Но что если вы добавите новые записи? Далее вы увидите, как создать формулы с динамическим диапазоном.
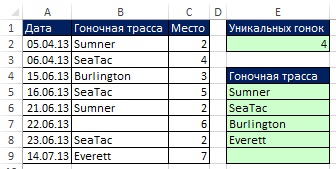
Рис. 19.12. Формула извлечения уникального списка
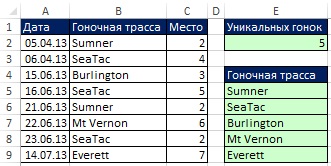
Рис. 19.13. В случае изменения исходных данных, формула обновления немедленно. Фильтр и Расширенный фильтр не могу обновиться автоматически без написания кода VBA
Формула массива: извлечение уникального списка из одного столбца с использованием динамического диапазона
Дополним последний пример тем, что вы узнали о формулах, использующих определенные имена на основе динамических диапазонов (глава 13). На рис. 19.14 приведена формула для определения имени Трасса. Эта формула предполагает, что вы никогда не введете запись после строки 51.
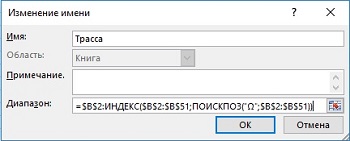
Рис. 19.14. Определение имени Трасса на основе формулы
Определив имя, вы можете использовать его в любой формуле. На рис. 19.15 показано, как использовать имя для подсчета числа уникальных значений (сравните с рис. 19.8). А на рис. 19.16 показана формула, извлекающая сами уникальные значения из списка гоночных трасс. Обратите внимание, что вместо фрагмента диапазон<>»» (как это было на рис. 19.8 и 19.10), используется функция ЕТЕКСТ (любой текст вернет значение ИСТИНА). При использовании ЕТЕКСТ, если вы введите число (как в ячейке В11), или любой иной не-текст, формулы проигнорирует это значение. На рис. 19.17 показано, что формула автоматически извлекает любые новые названия трасс, игнорируя числа.
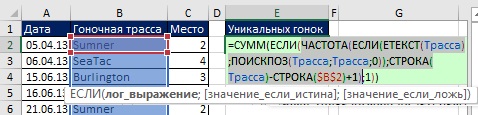
Рис. 19.15. Формула подсчета уникальных значений на основе динамического диапазона
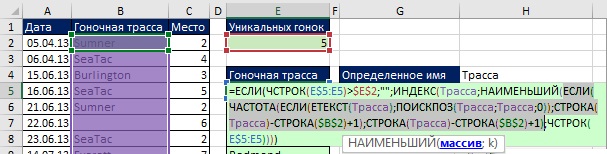
Рис. 19.16. Извлечение уникального имени трассы на основе динамического диапазона
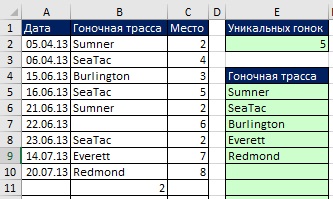
Рис. 19.17. Новые записи автоматически добавляются, а числа игнорируются
Создание формулы уникальных значений для выпадающего списка
Опираясь на только что рассмотренный пример, определим второе имя – ТрассаСписок, также основанное на динамическом диапазоне, но теперь ссылающееся на список уникальных трасс (диапазон Е5:Е14, рис. 19.18). Так как диапазон Е5:Е14 содержит только текстовые и пустые значения (тестовые строки нулевой длины – «»), в аргументе искомое_значение функции ПОИСКПОЗ можно использовать подстановочные знаки *? (что означает, по крайней мере, один символ). А в аргументе тип_сопоставления функции ПОИСКПОЗ следует использовать значение –1, что позволит найти последний элемент текста в столбце, содержащий, по крайней мере, один символ. Как показано на рис. 19.18, то вы можете использовать определенное имя в поле Источник окна Проверка вводимых значений (подробнее о создании выпадающего списка см. Excel. Проверка данных). Выпадающий список может расширяться и сжиматься, по мере того, как новые данные будут добавляться или удаляться в столбце В.
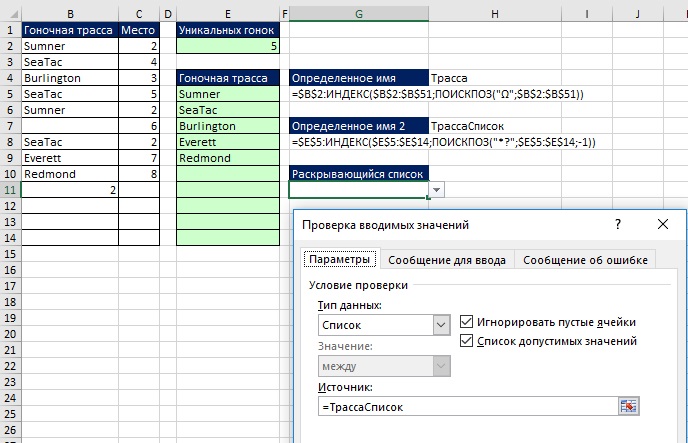
Рис. 19.18. Использование определенного имени на основе формулы динамического диапазона для раскрывающегося списка
Если подстановочные знаки должны обрабатываться, как обычные символы
Как вы узнали в главе 17, иногда подстановочные знаки должны рассматриваться как символы. На рис. 19.18 показано, как вы можете изменить формулы для таких случаев. Вы присоединяете тильду перед диапазоном аргумента искомое_значение функции ПОИСПОЗ и присоединяете пустую строку сзади к диапазону в аргументе просматриваемый_массив.
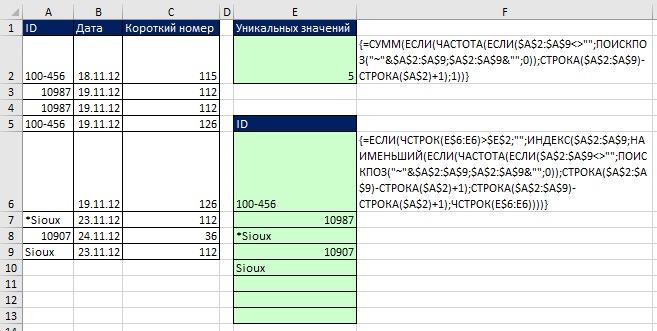
Рис. 19.19. Формулы, обрабатывающие подстановочные знаки, как обычные символы
Использование вспомогательного столбца или формулы массива для извлечения уникальных записей на основе критериев
В начале заметки было показано, что для извлечения уникальных записей на основе критериев отлично пойдет Расширенный фильтр. Однако, если вам требуется мгновенное обновление, вы можете использовать вспомогательный столбец (рис. 19.20) или формулы массива (рис. 19.21).
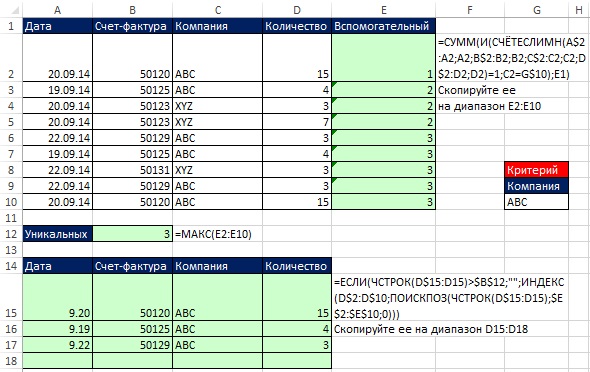
Рис. 19.20. Вспомогательный столбец для извлечения уникальных записей с одним условием
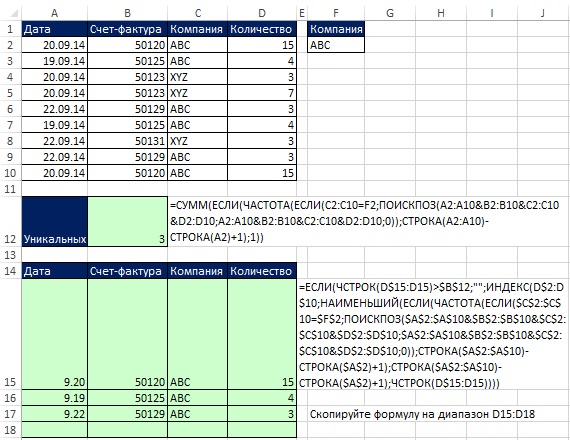
Рис. 19.21. Формулы массива для извлечения уникальных записей с одним условием
Динамические формулы для извлечения имен клиентов и объема продаж
Формулы показаны на рис. 19.22. Например, если добавить новую запись TT Trucks в строку 17, формула СУММЕСЛИ в ячейке F15 автоматически прибавит новое значение. Если добавить нового клиента в столбце В, он тут же отразиться в столбце Е, а формула СУММЕСЛИ в столбце F покажет новый итог.
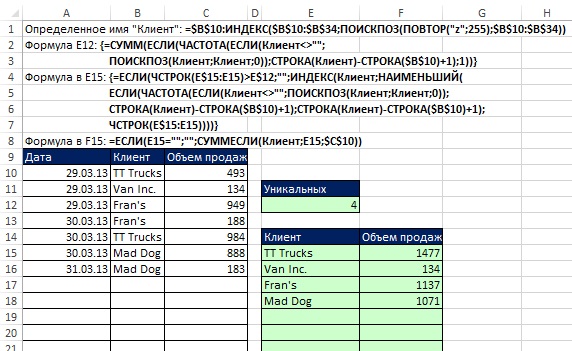
Рис. 19.22. Использование определенного имени и двух формул массива для извлечения уникальных клиентов и объема продаж
Обратите внимание, что функция СУММЕСЛИ в аргументе диапазон_суммирования содержит одну ячейку – $C$10. Вот, что на эту тему говорит справка формулы СУМЕСЛИ: аргумент диапазон_суммирования может не совпадать по размерам с аргументом диапазон. При определении фактических ячеек, подлежащих суммированию, в качестве начальной используется верхняя левая ячейка аргумента диапазон_суммирования, а затем суммируются ячейки части диапазона, соответствующей по размерам аргументу диапазон. Формулы, введенные в ячейки Е15 и F15, копируются вдоль столбцов.
Сортировка числовых значений
Формулы для сортировки чисел довольно простые, а вот для сортировки смешанных данных – безумно сложны. Поэтому, если вам не требуется мгновенное обновление, то лучше обойтись без формул, воспользовавшись опцией Сортировка. На рис. 19.23 приведены две формулы сортировки.
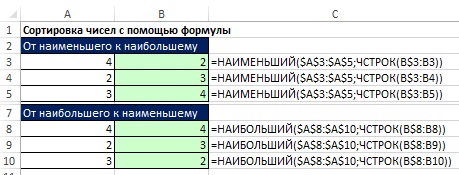
Рис. 19.23. Формулы сортировки чисел
На рис. 19.24 показано, как можно использовать вспомогательный столбец для сортировки чисел. Поскольку функция РАНГ не сортирует одинаковые числа (давая им один и тот же ранг), для их различения добавлена функция СЧЁТЕСЛИ. Обратите внимание, что функция СЧЁТЕСЛИ имеет расширенный диапазон, который начинается на одну строку выше. Это нужно для того, чтобы первое появление любого числа не давало вклада. Второе появление числа увеличит ранг на единицу. Эта последовательная нумерация устанавливает порядок, в котором функции ИНДЕКС и ПОИСКПОЗ извлекают записи в диапазоне А8:В12.
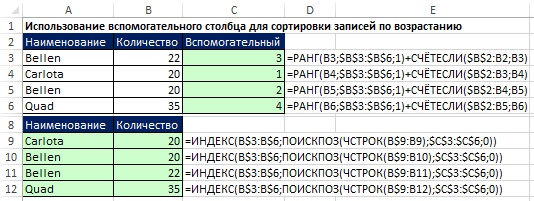
Рис. 19.24. Использование вспомогательного столбца для сортировки чисел по возрастанию
Если вы можете позволить себе создать вспомогательный столбец в области извлечения данных (диапазон А10:А14 на рис. 19.25), удобно применить описанную выше сортировку чисел на основе функции НАИМЕНЬШИЙ, и уже на основе ее извлечь наименования с помощью функции массива.
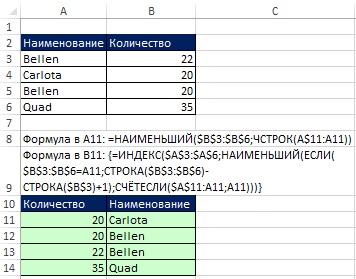
Рис. 19.25. Если вы не можете использовать вспомогательный столбец, примените сортировку на основе функции НАИМЕНЬШИЙ (в ячейке А11) и формулу массива (в ячейке В11)
Часто в бизнесе и спорте требуется извлечь N лучших значений и имена, связанные с этими значениями. Начните решение с формулы СЧЁТЕСЛИ (ячейка A11 на рис. 19.26), которая определит количество записей, подлежащих отображению. Обратите внимание, что аргумент критерий в функции СЧЁТЕСЛИ в ячейке А11 – больше или равно значению в ячейке D8. Это позволяет отобразить все пограничные значения (в нашем примере, хотя и требуется отобразить Тор 3, подходящих значения четыре).
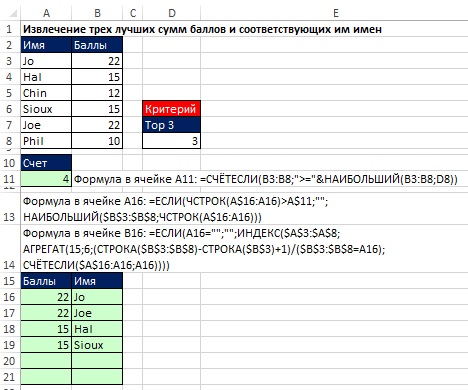
Рис. 19.26. Извлечение трех лучших сумм баллов и соответствующих им имен. При изменении N в ячейке D8 область А15:В21 будет обновляться
Сортировка текстовых значений
Если допустимо использование вспомогательного столбца задача не такая уж и сложная (рис. 19.27). Операторы сравнения обрабатывают текстовые символы на основе числовых кодов ASCII, приписанных символам. В ячейке С3 первая функция СЧЁТЕСЛИ возвращает ноль, а вторая –добавляет единицу. В С4: 2+1, С5: 0+2, С6: 3+1.
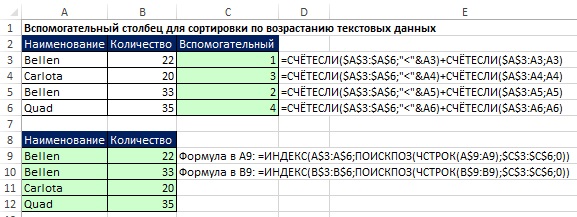
Рис. 19.27. Вспомогательный столбец для сортировки текстовых значений
Сортировка смешанных данных
Формула, которая позволяет извлекать из смешанных данных уникальные значения, а затем их сортировать, очень большая (рис. 19.28). При ее создании использованы идеи, которые встречались ранее в этой книге. Начнем изучение формулы с рассмотрения того, как работает стандартная функция сортировки в Excel.
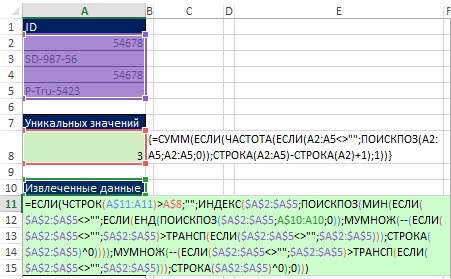
Рис. 19.28. Формула для извлечения и сортировки уникальных смешанных значений
Excel сортирует результаты в следующем порядке: сначала числа, затем текст (включая строки нулевой длины), ЛОЖЬ, ИСТИНА, значения ошибок в порядке их появления, пустые ячейки. Вся сортировка происходит в соответствии с кодами ASCII. Существует 255 кодов ASCII, каждому из которых соответствует номер от 1 до 255:
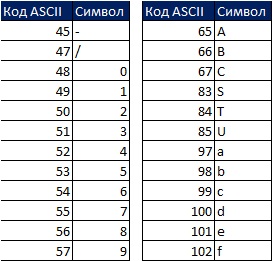
Например, число 5 соответствует коду ASCII 53, и символ S – коду ASCII 83. Если отсортировать два значения – 5 и S – от меньшего к большему, то 5 будет выше S, потому что 53 меньше 83.
Набор данных в диапазоне А2:А5 (рис. 29) в соответствии с правилами сортировки преобразуется в диапазон Е2:Е5. Чтобы лучше понять принципы сортировки рассмотрите значения в диапазоне С2:С5. Например, если вы задаете вопрос «Как много выше меня по рангу?» к ID в ячейке A2 (54678), ответ будет ноль, потому что в отсортированном списке, идентификатор 54678 будет самым верхним. У SD-987-56 будет три IDвыше него. Вам нужна формула, чтобы получить значения в диапазоне С2:С5.
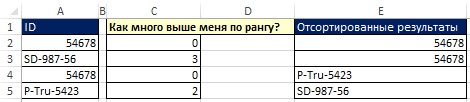
Рис. 19.29. Если вы отсортируете список по ID, P-Tru-5423 будет в нем третьим
Для начала выделите диапазон Е1:H1 и в строке формул наберите =ТРАНСП(А2:А5), введите формулу нажав Ctrl+Shift+Enter (рис. 19.30). Далее выделите диапазон Е2:H5 в строке формул наберите =А2:А5>Е1:Н1 и введите формулу нажав Ctrl+Shift+Enter (рис. 19.31). На рис. 19.32 показан результат, представляющий собой прямоугольный массив значений ИСТИНА и ЛОЖЬ, которые соответствуют каждой из ячеек в результирующем массиве, как ответ вопрос «Заголовок строки больше заголовка столбца?»
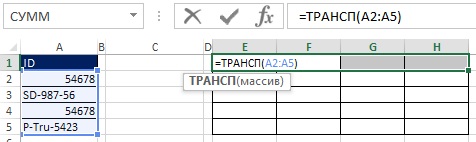
Рис. 19.30. Выделите диапазон Е1:H1 и введите формул массива
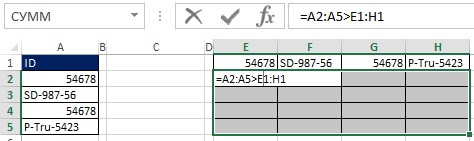
Рис. 19.31. В диапазоне Е2:Н5 введите формулу массива =А2:А5>Е1:Н1
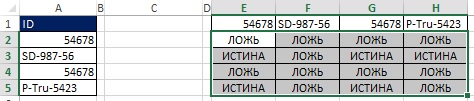
Рис. 19.32. Каждая ячейка диапазона Е2:Н5 содержит ответ вопрос «Заголовок строки больше заголовка столбца?»
Например, в ячейке Е3 задан вопрос: SD-987-56 > 54678. Так как 54678 меньше, чем SD-987-56, ответ ИСТИНА. Обратите внимание, что диапазон Е3:Н3 включает три значения ИСТИНА и одно ЛОЖЬ. Оглядываясь на рис. 19.29, можно увидеть, что именно число три находится в ячейке С3.
Как показано на рисунках 19.33 и 19.34, вы можете преобразовать значения ИСТИНА и ЛОЖЬ в единицы и нули путем добавления двойного отрицания к формуле массива. Поскольку исходный массив (Е2:Н5) имеет размерность 4×4, а результат вы хотите в виде массива 4×1, используйте функцию МУМНОЖ (см. рис. 19.35 и главу 18). Функция МУМНОЖ – это функция массива, поэтому введите ее нажав Ctrl+Shift+Enter (рис. 19.36). Теперь, вместо того, чтобы использовать диапазон Е2:Н5, добавьте соответствующие элементы внутрь формулы (рис. 19.37).
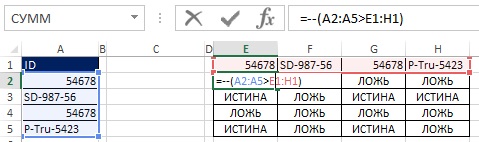
Рис. 19.33. Двойное отрицание преобразует значения ИСТИНА и ЛОЖЬ в единицы и нули
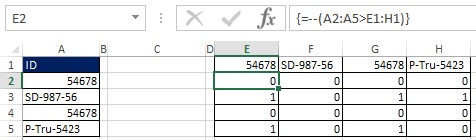
Рис. 19.34. Вместо массива значений ИСТИНА и ЛОЖЬ у вас массив нулей и единиц
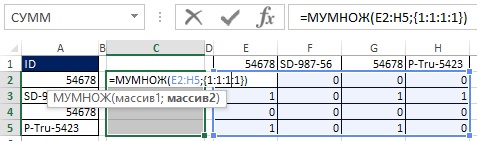
Рис. 19.35. Функция МУМНОЖ позволяет преобразовать матрицу 4×4 в 4×1
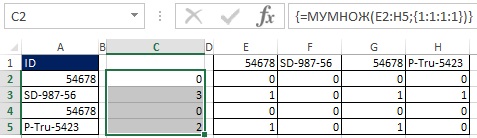
Рис. 19.36. Выбрав диапазон С2:С5 и введя функцию массива МУМНОЖ вы получаете колонку цифр, которые говорят, сколько ID в отсортированном списке выше выбранного
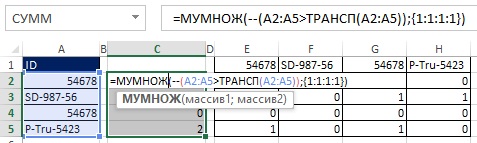
Рис. 19.37. Вместо использования вспомогательного диапазона Е2:Н5, соответствующие элементы добавлены внутрь формулы
На рис. 19.38 показано, как можно заменить массив констант фрагментом СТРОКА($A$2:$A$5)^0.
![]()
Рис. 19.38. Массив констант заменен элементом формулы на основе функции СТРОКА
Далее, вы хотите добавить проверку диапазона на отсутствие пустых ячеек, наличие которых приведет к тому, что МУМНОЖ вернет ошибку (рис. 19.39).
![]()
Рис. 19.39. Чтобы справиться с потенциальными пустыми ячейками все вхождения А2:А5 следует дополнить проверкой ЕСЛИ(А2:А5<>»»,А2:А5); функция СТРОКА не требует такого дополнения, т.к. функция работает с адресом ячейки, а не с ее содержимым
Поскольку окончательная формула будет использоваться в других местах, нужно сделать все диапазоны абсолютными (рис. 19.40). На рис. 19.41 показаны результирующие значения.

Рис. 19.40. Диапазоны А2:А5 превращены в абсолютные
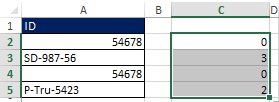
Рис. 19.41. Введите формулу с помощью Ctrl+Shift+Enter
Поскольку этот элемент будет дважды использоваться в дальнейшем, вы можете сохранить его под определенным именем. Как показано в диалоговом окне (рис. 19.42), формуле дано название СЗБ – Сколько Значений Больше.
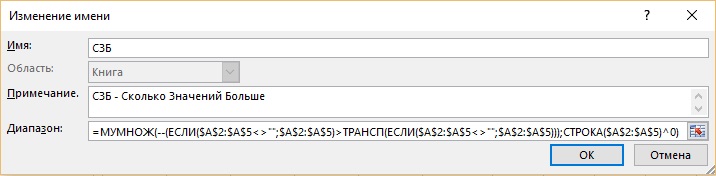
Рис. 19.42. Поскольку элемент формулы будет использоваться несколько раз, сохраните его под определенным именем
Далее вам нужно создать формулу для извлечения и сортировки уникальных значений (рис. 19.43). Обратите внимание:
- Аргумент массив функции ИНДЕКС ссылается на исходный диапазон А2:А5.
- Первая функция ПОИСКПОЗ сообщит функции ИНДЕКС относительную позицию элемента в массиве А2:А5.
- Пока аргумент искомое_значение функции ПОИСПОЗ оставлен пустым.
- Определенное имя (СЗБ) в аргументе просматриваемый_массив позволит вам в первый раз обратиться к элементу, имеющему значение 0, затем 2, и, наконец, 3.
- Ноль в аргументации тип_сопоставления задает точное совпадение, что позволит исключить обращение к дублям.
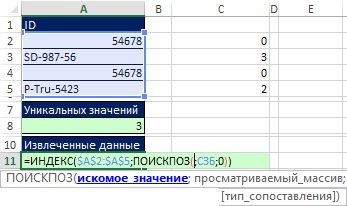
Рис. 19.43. Вы начинаете формулу для извлечения и сортировки данных в ячейке A11. Аргумент искомое_значение функции ПОИСПОЗ пока оставляете пустым
Прежде чем вы создадите аргумент искомое_значение функции ПОИСКПОЗ, вспомните, что, собственно, вам требуется. Есть три уникальных ID, которые нужно отсортировать, так что вам понадобятся три числа в аргументе искомое_значение по мере того, как формула будет скопирована вниз. Эти числа позволят найти относительную позицию в массиве А2:А5, которую и требуется предоставить функции ИНДЕКС:
- В ячейке A11, функция ПОИСКПОЗ вернет 0, что соответствует относительной позиции 1 внутри определенного имени СЗБ.
- Когда формула будет скопирована вниз в ячейку А12, функция ПОИСКПОЗ должна вернуть число 2, а относительная позиция = 4 внутри СЗБ.
- В ячейке A13 функция ПОИСКПОЗ должен вернуть 3, а относительная позиция = 2 внутри СЗБ.
Картина вырисовывается, когда вы думаете о том, что аргументу искомое_значение при копировании формулы вниз должен соответствовать запрос: «Дайте минимальное значение внутри определенного имени СЗБ, которое еще не использовалось». Как показано на рис. 19.44 элемент формулы МИН(ЕСЛИ(ЕНД(ПОИСКПОЗ($A$2:$A$5;A$10:A10;0));СЗБ)) возвращает минимальное значение при копировании формулы вниз, точно отвечая на запрос. Причина, по которой это работает, состоит в том, что во фрагменте ЕНД(ПОИСКПОЗ($A$2:$A$5;A$10:A10;0)) сравниваются два списка (см. главу 15). Обратите внимание на расширяющийся диапазон А$10:А10 в аргументе просматриваемый_массив. В ячейке A11 комбинация ЕНД и ПОИСКПОЗ помогает извлечь из СЗБ все уникальные числа, и предоставить их функции МИН. При копировании формулы вниз до ячейки А12, ID, который был извлечен в ячейке A11, опять присутствует в расширенном диапазоне и снова будет найден в диапазоне $А$2:$А$5. Однако, ЕНД возвращает ЛОЖЬ, и из СЗБ не извлечется значение 0. Чтобы увидеть это введите формулу массива на рис 19.44, нажав Ctrl+Shift+Enter, и скопируйте ее вниз.
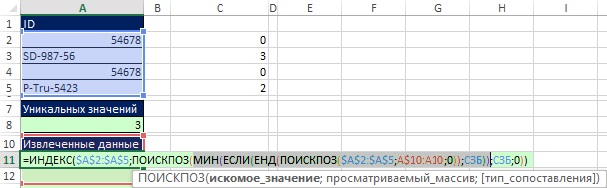
Рис. 19.44. Элемент формулы в аргументе искомое_значение функции ПОИСКПОЗ соответствует запросу: «Дайте минимальное значение внутри определенного имени СЗБ, которое еще не использовалось»
На рис. 19.45 показано, что в аргументе просматриваемый_массив второй функции ПОИСПОЗ диапазон А$10:А10 расширился до А$10:А11. Чтобы понять, как работает эта формула, последовательно выделяйте ее фрагменты, и кликайте на F9 (рис. 19.46–19,49).

Рис. 19.45. Расширяемый диапазон А$10:А11 сейчас (в ячейке А12) включает первый ID (54678)

Рис. 19.46. Комбинация функций ЕНД и вторая ПОИСКПОЗ поставляет массив логических значений; два значения ЛОЖЬ исключают нулевые значения из определенного имени СЗБ
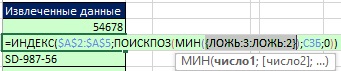
Рис. 19.47. Нули исключены и остаются только числа 3 и 2; число 2 является минимальным, поэтому именно оно должно быть извлечено следующим
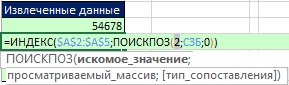
Рис. 19.48. Функция МИН выбирает число 2; теперь функция ПОИСКПОЗ может найти правильное относительно положение для функции ИНДЕКС
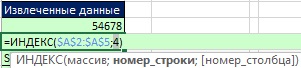
Рис. 19.49. Функция ИНДЕКС извлечет значение 2, которое соответствует относительной четвертой позиции ID в диапазоне А2:А5
Теперь, возвращаясь к ячейке А11, вы можете добавить еще одно условие так, чтобы пустые ячейки не влияли на формулу (рис. 19.50).
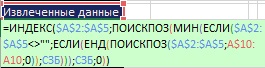
Рис. 19.50. Внутри функции МИН два условия; первое: «ячейки не пустые?», второе: «значение еще не использовалось?»
На рис. 19.51 приведена окончательная формула. В нее добавлено условие, чтобы строки в диапазоне А11:А15 оставались пустыми после того, как извлечены отсортированные уникальные значения. На рис. 19.52 показано, что произойдет, если ячейку А3 сделать пустой. Наше добавление для проверки пустых ячеек сработало.
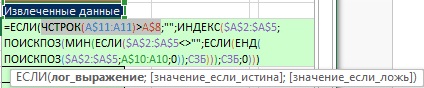
Рис. 19.51. Финальная формула
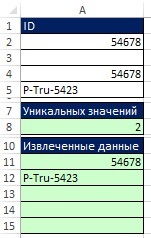
Рис. 19.52. Формула работает даже если есть пустые ячейки
Это было не просто. Но, если вы дочитали до этого места, я надеюсь, что вам понравилось.
Здравствуйте, Николай. Большое Вам спасибо за книгу Гирвина.Дочитал до самого конца и мне понравилось. Но я уверен, что есть способ решения последней задачи без формулы массива. И я почти уже подошёл к её решению. Точнее решил её, но неэлегантно. Объясню принцип:
1. Функция Агрегат(15;6;…) сама по себе отлично справляется с сортировкой и извлечением уникальных числовых значений и что самое удивительное, заставляет «под собой» работать без CSE практически всё и игнорирует ошибочные данные
2. Намного сложнее та же функция работает с извлечением и сортировкой уникально текста, но тоже справляется. Естественно в комбинации с ИНДЕКС. Для этого необходимо построить трёхэтажную дробь, в знаменателе сравнить с ещё одним Агрегатом и т.д. Оказалось, что «под собой» она как и СУММПРОИЗВ обрабатывает массивы, условия, сравнения
3. В чём неэлегантность?
По-моему, использование функции ЕСЛИОШИБКА, в «значении истина» ставится «комбинация для сортировки и извлечения уникальных Числовх значений, в «случае ошибки» -Комбинация для сортировки и извлечения уникального текста.
Итак: в ячейках B2-B11 любые данные, включая пустые ячейки
Формула:
Александр, я Сергей))
Спасибо за формулу. Поместил ее в Excel-файл.
Прошу прощения, Сергей! Я благодарю Вас