В связи с увлечением Fantasy Premier League меня заинтересовал рейтинг игроков на сайте livefpl.
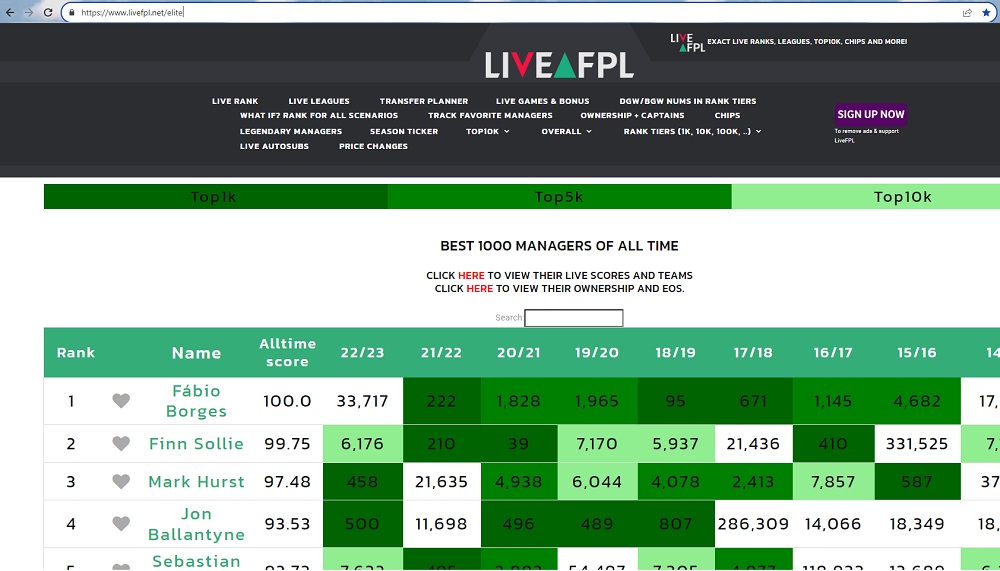
Рис. 1. Web-страница с рейтингом игроков
Скачать заметку в формате Word или pdf, примеры в формате Excel
Чтобы скачать таблицу, я открыл Excel, прошел по меню Данные –> Из Интернета, и в открывшемся окне ввел url-адрес https://www.livefpl.net/elite. После несложных преобразований я получил изящную таблицу:
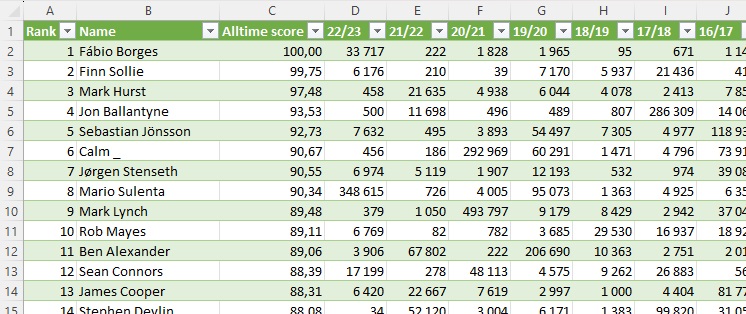
Рис. 2. Таблица в Excel с рейтингом игроков
С этой таблицей лишь одна проблема – в ней потеряны ссылки на официальные аккаунты игроков на сайте fantasy.premierleague.com.
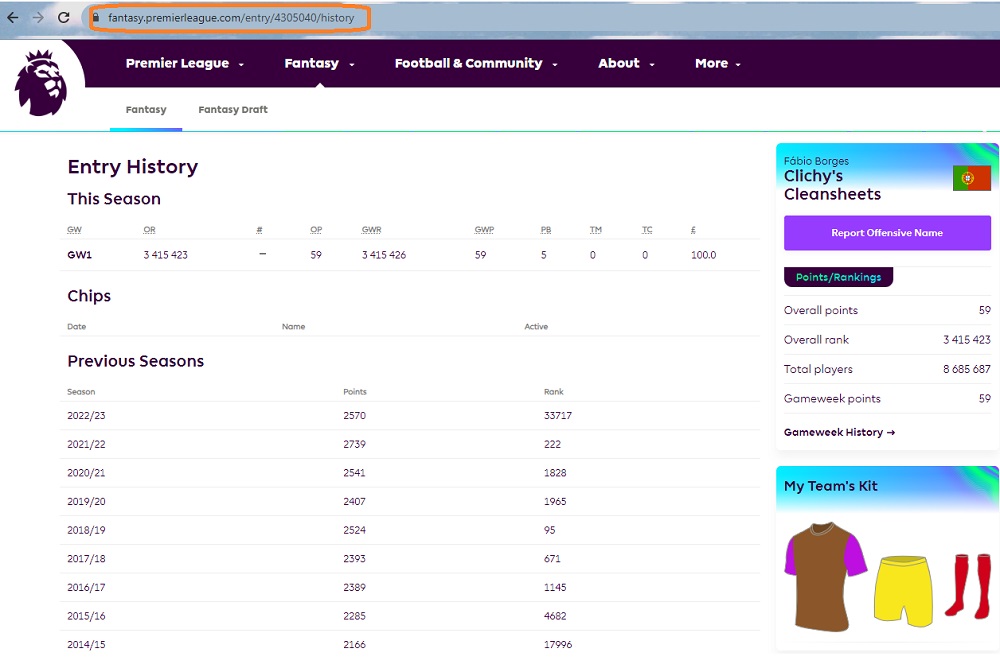
Рис. 3. Аккаунт #1 рейтинга livefpl Fábio Borges на сайте fpl; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Всё дело в том, что номер аккаунта указан не в самой таблице, а в виде web-ссылки, приклеенной к имени игрока:

Рис. 4. Ссылка на аккаунт fpl есть в html-коде страницы
При просмотре html-кода страницы эту ссылку можно найти (см. правую часть рис. 4). Как добраться до этой ссылки? Задал вопрос на форуме planetaexcel. Но ответа не получил.
Решение с помощью интерфейса редактора Power Query
Решение нашлось в статье эксперта в области Power Query Гила Равива. На русском языке вышла книга Гила Power Query в Excel и Power BI: сбор, объединение и преобразование данных.
При импорте рейтинга с сайта livefpl Power Query по умолчанию использует функцию Web.Page(Web.Contents("https://www.livefpl.net/elite"))

Рис. 5. Первый шаг запроса Power Query
Вот что сказано в справке Microsoft о функции…
|
1 |
Web.Page(html as any) as table |
… Возвращает содержимое документа HTML, разбитого на составные структуры, а также представление полного документа и его текста после удаления тегов.
А нам то нужны теги! Поэтому Гил предлагает убрать функцию Web.Page и оставить Web.Contents().
Эта функция…
|
1 |
Web.Contents(url as text, optional options as nullable record) as binary |
… возвращает содержимое, скачанное с адреса url в двоичном виде.
Однако в редакторе PQ в строке кода не получится заменить…
|
1 |
Web.Page(Web.Contents("https://www.livefpl.net/elite")) |
… на…
|
1 |
Web.Contents("https://www.livefpl.net/elite") |
Редактор автоматически вернет первоначальное значение. Не беда. Откройте расширенный редактор, и выполните замену:
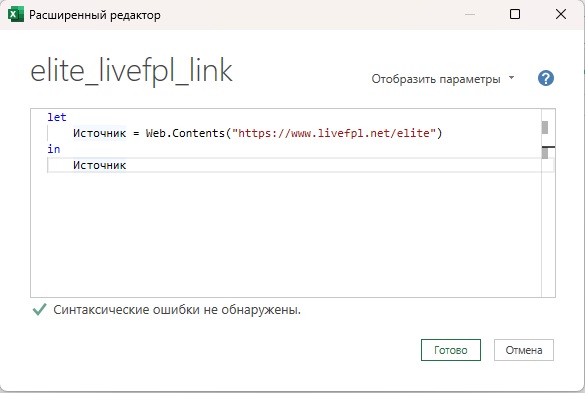
Рис. 6. Удаление функции Web.Page() в расширенном редакторе
Нажмите Готово. Вы увидите, что редактор PQ вернул двоичный файл:
Рис. 7. Функция Web.Contents() возвращает двоичный файл
Щелкните правой кнопкой мыши на файле и выберите Текст:
Рис. 8. Извлечение текста из двоичного файла
Эта команда интерфейса в редакторе PQ создаст строку кода…
|
1 |
= Table.FromColumns({Lines.FromBinary(Web.Contents("https://www.livefpl.net/elite"), null, null, 65001)}) |
Здесь функция Lines.FromBinary() преобразует двоичное значение в список текстовых значений, разделенных разрывами строк:
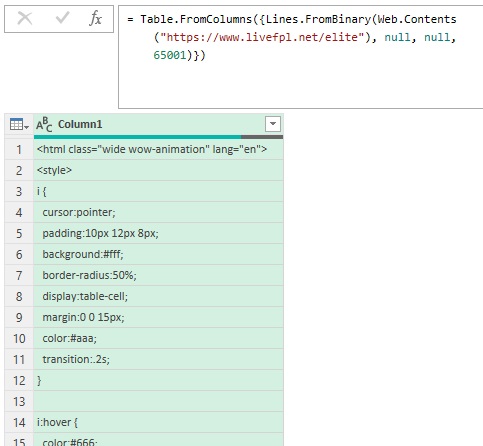
Рис. 9. Содержимое страницы livefpl.net/elite в виде html-кода
С помощью фильтра оставляем строки, содержащие текст history:
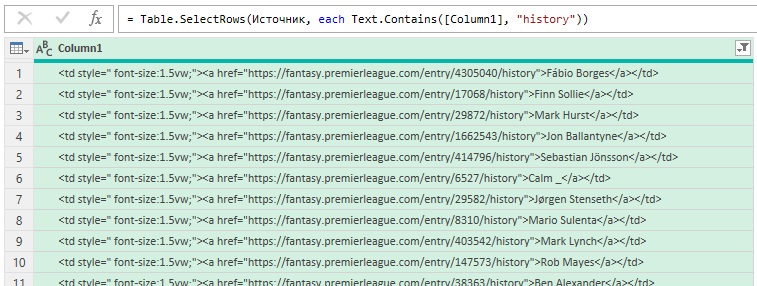
Рис. 10. Отфильтрованные строки
И, наконец, с помощью инструмента Столбец из примеров вкладки Добавление столбца сначала в отдельный столбец выделяем номер аккаунта, а затем имя игрока:
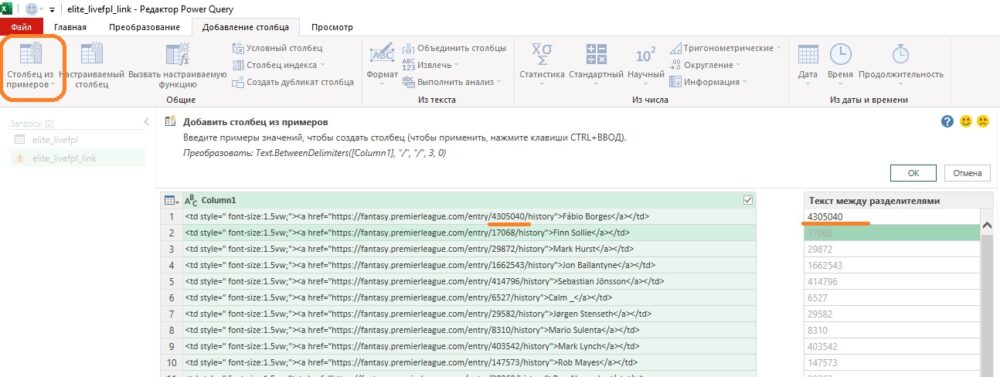
Рис. 11. Выделение номера аккаунта с помощью инструмента Столбец из примеров
Вуаля!
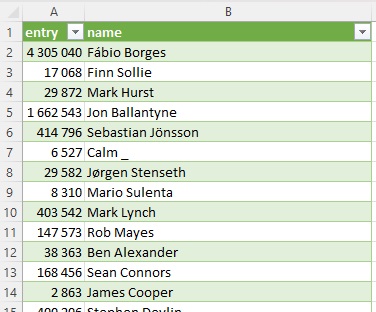
Рис. 12. Результат извлечения номеров аккаунтов из html-кода
Решение с использованием кода на языке М
В своих попытках найти решение я обратился в частной переписке к Михаилу Музыкину, эксперту по функциям языка М. Михаил предложил элегантное решение, которое позволяет в одном запросе получить и рейтинг и ссылки на аккаунты:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
let from = Binary.Buffer(Web.Contents("https://www.livefpl.net/elite")), table = Web.Page(from){0}[Data], links = List.Transform( List.Select( Text.Split( Text.FromBinary(from), "<a href=""" ), (x)=>Text.Contains(x,"https://fantasy.premierleague.com") ), (x)=>Text.Split(x,""""){0} ), to=Table.FromColumns(Table.ToColumns(table)&{links}) in to |
Несколько слов о том, как работает код. Точнее, как я это понимаю))
Web.Contents() извлекает бинарное содержимое страницы https://www.livefpl.net/elite.
Binary.Buffer() – помещает это содержимое в буфер. Во-первых, это ускоряет обработку, так как делается один запрос к странице https://www.livefpl.net/elite, а не два. Во-вторых, за время между обращениями за данными и web-ссылками содержимое страницы в Инете может измениться.
Web.Page(from) – возвращает содержимое страницы, разбитое на составные структуры в виде таблицы. Одна строка таблицы – одна структура. Как было сказано выше, теги удалены.
Web.Page(from){0} – возвращает первую строку таблицы.
Web.Page(from){0}[Data] – возвращает столбец Data первой строки таблицы, фактически ячейку. Поскольку в этой ячейке находится таблица, она возвращается в раскрытом виде.
Следующий фрагмент кода будем раскручивать из глубины.
Text.FromBinary(from) – возвращает текст из бинарного буфера, фактически html-код.
Text.Split(Text.FromBinary(from),"<a href=""") – разделяет html-код на элементы списка по разделителю
|
1 |
<a href=" |
List.Select() – фильтрует список, оставляя только элементы, удовлетворяющие условию:
|
1 |
(x)=>Text.Contains(x,"https://fantasy.premierleague.com") |
Суть этого условия: оставить элементы, которые содержат текст:
|
1 |
https://fantasy.premierleague.com |
List.Transform(list as list, transform as function) as list – в общем случае возвращает новый список, применяя функцию преобразования transform к списку list. В нашем случае в качестве функции используется
|
1 |
(x)=>Text.Split(x,"""") |
Text.Split() разбивает каждый элемент списка, используя в качестве разделителя кавычки ". Почему используется четыре кавычки? Первые и четвертые определяют, текстовую строку и внутри этих кавычек находится сам разделитель. Третьи кавычки – собственно разделитель. Вторые кавычки экранируют разделитель, поскольку оказалось, что он представлен специальным символом.
Функция…
|
1 |
(x)=>Text.Split(x,""""){0} |
… возвращает первый элемент списка.
Последний фрагмент сначала разбивает таблицу table на столбцы, затем добавляет столбец links, а затем объединяет все столбцы в таблицу to.
На самом деле ответ на вопрос "почему четыре кавычки" — это потому что это короче, чем Text.Split(txt,"#(0022)"), где между кавычками находится код символа (34) в шестнадцатеричной системе (22) )))
И в целом использована конструкция Text.Split(x,""""){0}, потому что она работает быстрее стандартного Text.BeforeDelimiter