Книга написана настоящим ученым. Важные социальные явления рассматриваются с научных позиций. Некоторые из приведенных здесь 10 уравнений мне были знакомы ранее, о других узнал впервые. В основе многих явлений жизни лежит математика. Её точность позволяет приходить к интересным выводам. Если научиться вычленять из происходящего данные и математические модели, то вы начнете видеть взаимосвязи. Более того, вы сможете управлять процессами, которые другим кажутся хаотичными.
Дэвид Самптер. Десять уравнений, которые правят миром. – М.: Манн, Иванов и Фербер, 2022. – 288 с.

Скачать краткое содержание в формате Word или pdf (конспект составляет около 6% от объема книги), примеры в Excel
Глава 1. Уравнение ставок
![]()
где x — коэффициент букмекера на победу фаворита. Коэффициент здесь понимается в британском формате: если он составляет 3 к 2 или x = 3/2, это означает, что на каждые поставленные 2 фунта в случае победы чистый выигрыш составляет 3 фунта.
Ни одна математическая модель не предсказывает победу или поражение с абсолютной точностью. Модель лишь говорит о вероятности того, что выиграет фаворит, и эта вероятность — число от 0 до 100%. Оно определяет уровень уверенности, который я приписываю результату.
Если α = β = 1, уравнение (1) упростится
![]()
Если, скажем, коэффициент был 3/2 (2,5 в европейской системе или +150 в американской), вероятность того, что фаворит выиграет, равна
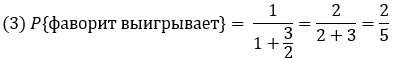
Британский (или дробный) коэффициент – отношение чистой прибыли к ставке. В нашем случае отношение 3/2 означает, что мы ставим 2 фунта, чтобы в случае победы получить чистую прибыль 3 фунта. Европейский (десятичный) коэффициент, который используется и в России, — это число, на которое умножается ставка для определения потенциальной выплаты. В нашем случае коэффициент 2,5 означает, что при ставке в 2 фунта мы получаем 2 × 2,5 = 5 фунтов, чистая прибыль снова составляет 3 фунта. Американский коэффициент — это потенциальная чистая прибыль при ставке в 100 условных единиц (он может быть положительным или отрицательным). В нашем случае +150 означает, что на каждые 100 единиц ставки можно получить 150 единиц чистой прибыли. Для ставки в 2 фунта чистая прибыль равна 3 фунтам.
Уравнение (1) без α и β дает оценку букмекера на победу фаворита. Он считает, что шансы фаворита на победу в матче составляют 2/5, или 40%. В остальных 60% случаев будет ничья или победит аутсайдер.
Без α и β уравнение ставок несложно понять. Однако без α и β оно не принесет денег. Поставим 1 фунт на фаворита. Если коэффициент букмекера верен, два раза из пяти вы выиграете 1,5 фунта, а три из пяти проиграете по 1 фунту. Средний выигрыш = 0.
Здесь неявно предполагается, что коэффициенты букмекеров справедливы. На самом деле нет. Букмекеры всегда подправляют их, чтобы ситуация складывалась в их пользу. Вместо того, чтобы предложить 3/2, заявят, скажем, 7/5.
Но есть способ обыграть букмекеров — изучить ставки и реальные результаты, и вычислить α и β. Я скачал коэффициенты и результаты для всех матчей чемпионатов мира и Европы, включая отборочные игры, начиная с чемпионата мира в Германии в 2006 году. Вот фрагмент нашей большой таблицы:
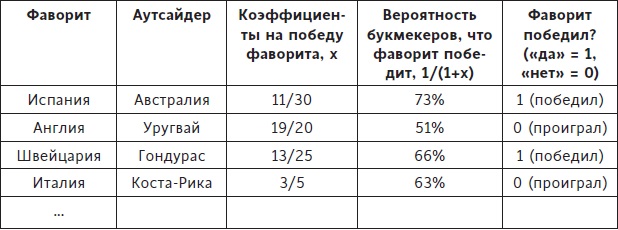
Рис. 1. Коэффициенты ставок и результаты
Насколько точны коэффициенты ставок? Для этого надо сравнить два последних столбца. Например, в матче между Испанией и Австралией на чемпионате мира 2014 года коэффициенты дают вероятность 73%, что Испания выиграет, и она действительно победила. Это можно считать «хорошим» прогнозом. А вот Коста-Рика обыграла Италию, хотя коэффициенты давали 63% на победу итальянцев, — «плохой» прогноз.
Я пишу слова «хороший» и «плохой» в кавычках, поскольку нельзя сказать, хорош или плох прогноз, если нет альтернативы, с которой его можно сравнить. Вот здесь и появляются α и β. Их называют параметрами уравнения (1). Это величины, которые мы можем менять для тонкой настройки уравнения, чтобы сделать прогноз точнее.
Для оценки α и β мы использовали логистическую регрессию. На исторических данных наилучшие прогнозы получались при α = 1,16 и β = 1,25. То, что оба параметра превосходят 1, говорит о сложной связи между коэффициентами и исходами матчей. Проще всего понять эту связь путем добавления к нашей таблице еще одной колонки и сравнения нашей модели логистической регрессии с прогнозами букмекеров.
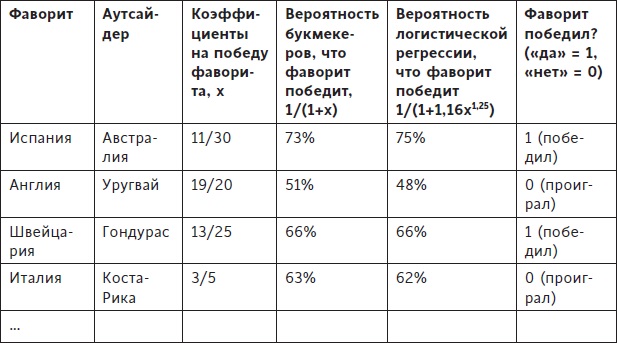
Рис. 2. Уточненный прогноз для α = 1,16 и β = 1,25
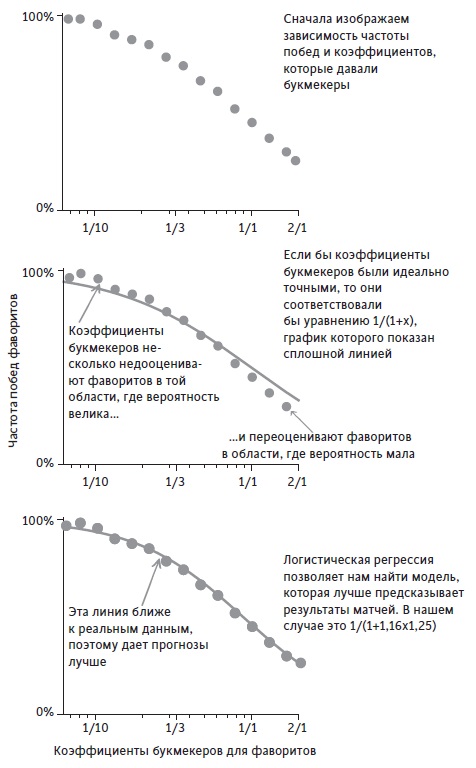
Рис. 3. Иллюстрация того, как логистическая регрессия дает оценки α = 1,16 и β = 1,25
Глава 2. Уравнение суждений
Если во время полета началась сильная тряска, вряд ли вы падаете. Если во время купания на австралийском побережье вам кажется, что вы видите в воде нечто пугающее, вероятность того, что это акула, крохотная. Вы можете волноваться, когда ваши близкие возвращаются поздно домой, а вам не удается с ними связаться, но вероятнее всего, что они просто забыли зарядить телефон. Многое из того, что мы считаем новой информацией — тряска самолета, неясные фигуры в воде или отсутствие звонков, — не так уж страшно, если подходить к проблеме правильно.
Теорема Байеса позволяет вам верно оценивать важность информации и сохранять спокойствие, когда все вокруг паникуют. Первый шаг к математическому подходу к миру — понять, как мы используем модели. Теорема Байеса – связь, которую нам нужно установить между моделью и данными. Она позволяет нам проверить, насколько хорошо наши картинки соотносятся с реальностью. Будем использовать букву M для модели и D для данных. Вероятность того, что модель верна, при условии истинности данных:
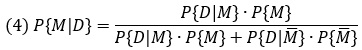
В числителе Р{М} — вероятность того, что модель истинна, до того, как произошло некое событие. Р{D|М} – вероятность, что мы наблюдаем некоторые конкретные данные, если наша модель верна. В знаменателе первое слагаемое равно числителю, а второе относится к априорной вероятности альтернативной гипотезы Р{М̅} и вероятности наблюдать эти же данные, если верна альтернативная модель Р{D|М̅}.
Первый урок, который нужно извлечь из формулы Байеса (уравнения суждений), – не надо торопиться с выводами. Нужно больше, чем один грязный комментарий, чтобы поставить на человеке клеймо. Если я вижу, что некто, с кем я работаю, совершил ошибку, я жду развития ситуации. Вполне может оказаться, что неправ был я.
Байесовское мышление изменило принципы науки в последние десятилетия. Оно идеально соответствует научному взгляду на мир. Экспериментаторы собирают данные (D), а теоретики разрабатывают гипотезы или модели (M). Формула Байеса объединяет оба эти компонента.
Формула Байеса работает не только с объективными вероятностями, но и с субъективными. Она дает нам возможность рассуждать о числах, даже если они не абсолютно точные. Мы можем поменять их и получить другие результаты, но нельзя изменить логику, которую нам рекомендует байесовский подход.
Многие, даже математики и другие ученые, не осознают, что настоящая сила байесовского подхода в том, как он заставляет вас определить, что вы думали до эксперимента и после него. Байесовский анализ требует, чтобы вы разбили свои рассуждения на модели и по очереди искали свидетельства для каждой. Вы можете считать, что данные подтверждают ваше предположение, но нужно быть честным в отношении того, насколько сильно вы поддерживали свою гипотезу до этого эксперимента.
Глава 3. Уравнение уверенности
Следующее уравнение дает оценку уверенности в каком-либо событии.
![]()
Представьте, что я 400 раз запускаю рулетку, ставя по 1 фунту на красное. На рулетке 37 номеров: от 1 до 36, раскрашенные поочередно в красный и черный цвета, и зеленый 0. Он обеспечивает преимущество казино. Вероятность красного = 18/37, и в случае этого события я получаю 2 фунта. Вероятность потери денег (непопадания шарика на красный цвет) = 1 – 18/37 = 19/37. Ожидаемый (средний) выигрыш при ставке в 1 фунт составляет 1 * 18/37 – 1 * 19/37 = –1/37; поэтому при каждом повороте колеса я в среднем проигрывает 2,7 пенса.
Средний проигрыш h = –0,027. За 400 попыток проиграю в среднем h * n = 0,027 * 400 = 10,8 фунта. Следующий шаг — определить степень отклонения от среднего. Для этого найдем средний квадрат разности между результатом одного вращения и средним значением. Среднее значение h = –0,027 фунта, и если мы выиграли фунт, то квадрат разности равен (1 – (–0,027))2 = 1,0548, а если проиграли 1 фунт, то (–1 – (–0,027))2 = 0,9467. Есть 18 удачных исходов и 19 неудачных, поэтому средний квадрат разности:
![]()
σ2 называют дисперсией. У рулетки она очень близка к единице, но не равна ей. Если бы на рулетке было 36 номеров, половина красных и половина черных, дисперсия была бы в точности единица.
Дисперсия увеличивается пропорционально количеству вращений колеса. При n попытках дисперсия равна n * σ2. Обратите внимание, что при вычислении дисперсии мы возводим разность в квадрат, поэтому ее размерность — фунты в квадрате, а не фунты. Чтобы получить снова фунты, можно извлечь из дисперсии квадратный корень и получить так среднеквадратичное (стандартное) отклонение σ:
![]()
Число 1,96 в уравнении (5) появляется из математической формулы, которая описывает кривую нормального (гауссовского) распределения. В нашем случае колокол имеет максимум в среднем значении (10,8 фунта).
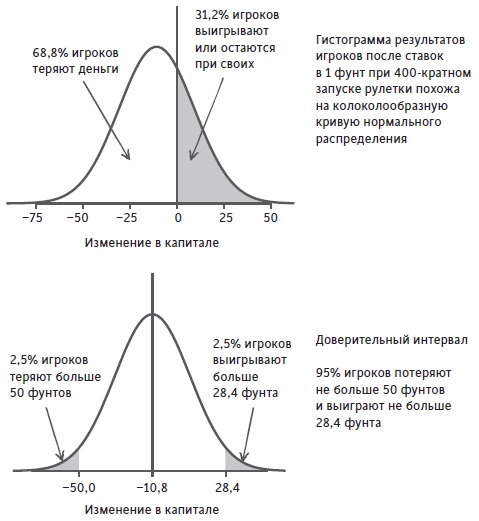
Рис. 4. Кривая нормального распределения для 400 запусков рулетки и ставок по 1 фунту
Интервал, который содержит 95% площади колоколообразной фигуры определяется уравнением (5)
![]()
Нейт Сильвер, создатель и редактор сайта спортивных и политических прогнозов FiveThirtyEight, для объяснения таких ситуаций использует термины «сигнал» и «шум» (подробнее см. Нейт Сильвер. Сигнал и шум). В спортивных ставках значение средней прибыли (или потери) при одной ставке (h) — это сигнал. Если у кого-то есть преимущество в 3%, то в среднем на каждую ставку в 1 фунт он выиграет 3 пенса. Шум при ставке измеряется величиной среднеквадратичного отклонения σ. Шум в спортивных ставках гораздо больше, чем сигнал. Например, если ставить 1 фунт на какую-то команду с шансами 1/2, то можно выиграть 1 фунт, либо выиграть 50 пенсов. С помощью формулы (7) можно вычислить, что σ = 0,7132. Таким образом, шум (σ = 0,71) при одной ставке гораздо больше, чем сигнал (h = 0,03). Отношение сигнала к шуму в нашем случае h/σ = 0,03/0,71 ~ 1/24.
Есть простое эмпирическое правило, которое можно использовать, чтобы узнать, сколько наблюдений нужно, чтобы надежно определить сигнал:
![]()

Рис. 5. Число наблюдений, необходимое для обнаружения слабых сигналов
Мои знакомые, делающие ставки на спорт, своё главное преимущество основывают на национальных различиях. Бразильцы ожидают больше голов в своих матчах, чем забивают на самом деле. Немцы — пессимисты и предпочитают ставить на скучные 0:0. Норвежцы отличаются точностью. Идеально рациональные скандинавы.[1]
Благодаря уравнению уверенности идеологические споры и теоретические рассуждения были вытеснены за пределы социальных наук. Внезапно с помощью Facebook и Instagram исследователи смогли измерить наши социальные связи. Они смогли использовать государственные базы данных, чтобы определить факторы, которые заставляют нас переходить с одной работы на другую и менять место жительства. Благодаря доступности данных и статистических тестов, определивших доверительный уровень для каждого случая, раскрылась структура нашего общества.
Глава 4. Уравнение умений
Специалисты по прикладной математике разделяют все, что вам говорят, на три категории. Первые две обсуждались в предыдущих главах: это модель и данные. Модели — наши гипотезы о мире, а данные — опыт, который позволяет нам установить истинность или ложность наших гипотез. Но некоторые рассказчики создают третью категорию: бес-смыслица. Он рассказывает истории о своих триумфах, неудачах и ощущениях, но ничего конкретного о том, как он думает или что он знает.
Дефис в слове «бес-смыслица» позаимствован у философа Алфреда Джулса Айера. Он использовал его для описания информации, которая не исходит от наших чувств. Бес-смыслица не основана на наблюдениях или на том, что можно измерить. Айер изложил эти идеи в книге «Язык, истина и логика», опубликованной 1936 году.
Основа большинства математических моделей для измерения умений — уравнение, выражающее так называемое марковское свойство (марковость):
![]()
Величина P(St+1|St) определяется так же, как в уравнении (4). P означает вероятность того, что мир будет находиться в состоянии St+1 в момент времени t + 1, при условии, что ранее он находился в состоянии St в момент времени t.
Ключевая идея марковости в том, что будущее зависит только от настоящего, но не от прошлого, которое привело нас к этому настоящему. Уравнение (10) говорит, что будущее состояние в момент времени t + 1 зависит только от состояния в настоящее время t, так что мы предполагаем, что прошлые состояния St–1, St–2, …, S1 роли не играют. Это и выражает уравнение, приравнивая левую и правую части.
Для примера представим Эдварда, бармена в оживленном заведении. Обозначим St количество людей, которые ожидают заказа в минуту t. В момент начала его смены обслуживания ждут S1 = 2 человека. Он наливает пару пинт первому парню в очереди и приносит бокал вина женщине за ним. Пока он обслуживает этих двоих, в очереди появляются еще трое, поэтому в минуту t = 2 в очереди S2 = 3 человека. Эд всех их обслуживает и видит, что в минуту t = 3 ждут уже S3 = 5. На этот раз он успевает обслужить только трех человек, а двое остаются, плюс за следующую минуту к ним добавляются еще четверо, и S4 = 6.
Марковское предположение говорит, что для измерения умений Эда достаточно знать скорость обслуживания клиентов: нам требуется знать, как St+1 зависит от St. Количество людей, которые ждали ранее в тот вечер не играет роли в анализе его умений в данный момент. Для оценки мастерства бармена это вполне разумное предположение. Эдвард может обслуживать примерно двух-трех человек в минуту — это разность между St+1 и St.
Уравнение (10) отличается от предыдущих тем, что не дает ответа сразу. В предыдущих уравнениях мы закладывали данные в модель и улучшали свое понимание настоящего или ближайшего будущего. Уравнение (10) – предположение.
Ключ к построению полезной модели — решить, какие сделать предположения. Модель Бога брала бы в таком качестве все, что когда-либо происходило в прошлом. Например, для баскетбольного гения Леброна Джеймса оценке включала каждую тренировку, на которую он приходил, каждый матч, где он играл, что ел на завтрак в течение всей жизни, как завязывал шнурки перед матчем. Это правая сторона уравнения (10). В качестве данных берется вся жизнь Джеймса до момента его броска. Создатель модели должен решить, что можно проигнорировать. Что из этого оставить в левой части уравнения (10), когда он делает марковское предположение.
Фильм Moneyball (в российском прокате «Человек, который изменил всё») — история бейсбольного тренера Билли Бина, сыгранного Брэдом Питтом, об одном из самых фанатичных применений статистики всех времен. Фильм рассказывает, как генеральный менеджер клуба-аутсайдера «Окленд Атлетикс» с небольшим бюджетом собрал команду из малоизвестных игроков на основе их статистических показателей. Команда в итоге выдала серию из двадцати побед подряд.
Уравнение умений предлагает вам быть честными в отношении начальных предположений. Не оправдывайте свою неудачу, утверждая, что пытались достичь чего-то другого, и не преуменьшайте успехи, отвлекаясь на неудачи в других сферах своей жизни. Однако прежде чем продолжить, заново проанализируйте свои предположения. Оцените, в чем вы хотите стать лучше. Не зацикливайтесь на истории. Используйте марковское предположение, чтобы забыть прошлое и сосредоточиться на будущем.
Глава 5. Уравнение влияния
Вообразим, что завтра я могу проснуться кем-то иным. Тогда то, кем я проснусь, определяется уравнением влияния:
![]()
Здесь A – переходная матрица, pt – вектор, определяющий вероятность проснуться кем-то иным в момент времени t. Для удобства подпишем строки и столбцы матрицы именами людей. На пересечении стоит вероятность проснуться иным человеком. Пусть в мире пять человек: я, Дуэйн «Скала» Джонсон, Селена Гомес и еще двое, о ком я никогда не слышал: назову их Ван Фан и Ли Вэй.
Пусть вероятности определяются подписками в Instagram. Скала застрял на какой-то математической задачке и решил подписаться на меня в Instagram. Селена Гомес познакомилась с Ван Фан и Ли Вэем на одном из своих концертов, и подписалась на них. Разумеется, все подписаны на Селену и на Дуэйна. Тогда мы имеем:
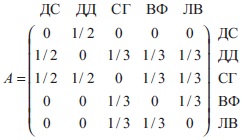
Рис. 6. Переходная матрица
Для меня, Дэвида Самптера, есть только два возможных варианта на завтрашний день: Селена или Скала. Поэтому в каждой из соответствующих клеток в моем столбце стоит 1/2. То же верно и для Скалы Джонсона. Остальные жители планеты могут перейти в трех других людей. Нули по диагонали матрицы отражают тот факт, что мы не можем остаться собой второй день подряд, потому что не подписаны на себя.
Для модели я использовал марковское свойство (уравнение 10): предположил, что то, кем я был два дня назад, никак не влияет на то, кем оказался сегодня. По сути, матрица A определяет цепь Маркова: она дает нам переходные вероятности для перемещения из одного состояния в другое, при этом следующее состояние зависит только от нынешнего, но не более ранних.
Будем постепенно двигаться по дням с помощью матрицы A. В первое утро я проснулся Дэвидом Самптером. Тогда вероятность, кем я стану завтра:
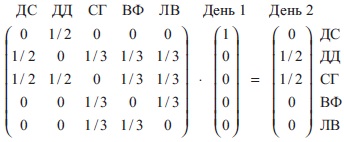
Рис. 7. Вектор в момент времени t = 2 (второй день)
Два столбца чисел в скобках по обеим сторонам от знака равенства называются векторами. Каждый элемент вектора — число от 0 до 1, которое определяет вероятность того, что я окажусь определенным человеком в определенный день. В день 1 я Дэвид Самптер, так что число в моей строке равно 1, а остальные элементы вектора — 0. В день 2 я могу оказаться либо Селеной Гомес, либо Дуэйном Джонсоном (поскольку Дэвид Самптер подписан только на них), и в этом векторе есть два числа 1/2 для них, а остальные равны 0.[2]
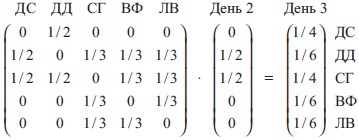
Рис. 8. Вектор в момент времени t = 3
Произведем умножение еще раз, чтобы найти, кем я могу оказаться в день 4.
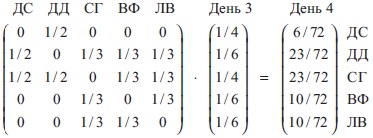
Рис. 9. Вектор в момент времени t = 4
Мы видим, как знаменитости выходят на центральные роли. Что произойдет через большой промежуток времени? Именно на этот вопрос и отвечает уравнение (11). Поскольку прошло бесконечно много времени, разницы между t и t + 1 нет. Можем заменить эти индексы значком бесконечности. Спустя достаточно много дней вероятность оказаться в некотором теле будет постоянной и определяться вектором р∞. Назовем его стационарным распределением.[3]

Рис. 10. Стационарное распределение
Twitter, Facebook и Snapchat дают возможность распространять информацию и влиять на чувства и мысли подписчиков. Стационарное распределение р∞ измеряет такое влияние; и не только с точки зрения того, кто на кого подписан, но и с точки зрения скорости, с которой тот или иной мем или идея распространяется среди пользователей. Люди с большими вероятностями в векторе р∞ влиятельнее и распространяют мемы быстрее.
Вот почему уравнение (11) — уравнение влияния — так ценно для сетевых гигантов. Измерение влиятельности — всего лишь вопрос матричной алгебры, и этим бездумно и некритично занимается компьютер. Изначально уравнение влияния применила Google при разработке своего алгоритма ранжирования страниц PageRank. За последние два десятилетия это привело к неожиданному результату. Система, которая первоначально создавалась для измерения влияния, превратилась в его создателя. Алгоритмы на базе уравнения влияния определяют, какие публикации должны занимать видное место в социальных сетях. Идея в том, что если некто популярен, то этого человека желают выслушать больше людей. Результатом становится цикл обратной связи: чем влиятельнее человек, тем большую заметность дает ему алгоритм, а от этого его влияние еще больше растет.
Уравнение влияния описывает распространение мемов и фейковых новостей, изучает, как соцсети создают маленький мир, в котором все соединены через шесть рукопожатий, и потенциальную возможность поляризации. Уравнение управляет лентой новостей Facebook, чтобы посмотреть, как пользователи реагируют, получая только негативные новости; создает кампании в сетях, чтобы побудить людей голосовать на выборах; конструирует фильтры, чтобы пользователи читали больше тех новостей, которые им интересны.
Когда Instagram изменил свои алгоритмы, оказалось, что настоящие влиятельные лица в сети не те, кто публикует снимки своей еды и моментов жизни. Скорее, это программисты Google, Facebook и Instagram, конструирующие фильтры, через которые мы смотрим на мир. Они решают, кто популярен и что популярно. Подумайте о том, как соцсети влияет на вашу самооценку и как контролирует информацию, к которой вы имеете доступ.
Глава 6. Уравнение рынка
Нельзя раскрыть секреты финансовых рынков, не начав с фундаментального уравнения:
![]()
Это уравнение описывает, как меняется величина X, которая представляет «ощущение» инвесторов в отношении текущей стоимости какой-то акции. Это ощущение может быть положительным или отрицательным, так что X = –100 означает плохое ощущение о будущем, а X = 25 — довольно хорошее. В нашей модели бычий рынок в будущем положителен (X > 0), а медвежий отрицателен (X < 0). Не приписывайте Х конкретную единицу измерения. Вместо этого думайте об X как об улавливании эмоций. Это могут быть не инвесторы, а чувства на собрании, когда объявляют о сокращении рабочих мест, или ощущение после того, как ваша компания получила большой заказ.
dX обозначает изменение X, т.е., изменение в ощущении. В правой части уравнения три слагаемых — hdt, f(X)dt и σ∙εt. Самая важная часть – сигнал h, далее обратная связь f(X) и стандартное отклонение σ (или шум). Коэффициенты, на которые умножены эти величины, указывают, что мы интересуемся изменениями (d) во времени (t). Шум умножается на εt – небольшие случайные отклонения во времени. Эти слагаемые моделируют наши ощущения в виде комбинации сигнала, социальной обратной связи и шума.
Первые экономисты (Адам Смит, Вильфредо Парето) ввели в уравнение только сигнал. Первые редкие признаки нестабильности — тюльпанная лихорадка в Голландии или крах Компании Южных морей — давали мало реальных оснований для беспокойства. Только после распространения капитализма по всему миру для взлетов и падений потребовались объяснения. От Великой депрессии 1929 года до биржевого краха 1987-го повторяющиеся кризисы демонстрировали обществу, что рынки несовершенны — они могут быть беспорядочными, со значительными колебаниями. Шум стал таким же сильным, как сигнал.
В 1900 году французский математик Луи Башелье опубликовал свою диссертацию «Теория спекуляций», в которой добавил второй компонент в уравнение (12) – шум. На протяжении большей части XX века новым источником прибыли стал шум. Для разработки и определения цены деривативов, фьючерсов и опционов используются дальнейшие развития базовой теории, например, модель Блэка – Шоулза.
Точно так, как ньютоновский детерминистический анализ был неправильной моделью финансовых рынков, во взгляде на бомбардировку рынка шумами отсутствовал один крайне важный элемент: мы участники рынка. Мы не частицы, на которые воздействуют какие-то события; мы активные агенты, одновременно и рациональные, и эмоциональные. Мы ищем сигнал в шуме и влияем на других людей, учимся у них, манипулируем ими.
Большие отклонения нельзя объяснить в терминах подбрасывания монеты и нормального распределения. Количество орлов после n бросков обычно лежит в интервале размера, пропорционального √n. Ключевое предположение, необходимое для применения центральной предельной теоремы, — независимость событий. Мы складываем результаты независимых вращений рулетки или спрашиваем независимые мнения множества разных людей.
Но колебания будущих цен на акции могут оказаться пропорциональными более высоким степеням n, например n2/3 или даже самой величине n. Это делает рынок крайне волатильным, а прогнозы почти невозможными. Причина этих колоссальных колебаний в том, что трейдеры не действуют независимо друг от друга. Участники фондового рынка – стадные животные, которые следуют друг за другом и в подъемах, и в спадах.
Новая математика, стоящая за большими уклонениями, была обнаружена несколькими специалистами. Две книги Нассима Талеба — Одураченные случайностью и Черный лебедь — содержат занятно высокомерный, но исключительно прозорливый анализ финансового мира до 2007 года. Книга американского экономиста Роберта Шиллера Иррациональный оптимизм, написанная примерно в то же время, дает более академичное и тщательное изложение близких идей.
Уравнение рынка говорит о том, от чего зависит стоимость на рынке, но не предсказывает цен, ни в краткосрочной, ни в долгосрочной перспективе. Почти вся информация в СМИ – бессмысленный шум или социальная обратная связь. Это бес-смыслица. Нельзя получить ничего полезного, наблюдая за ежедневными изменениями цены акций или за экспертами, объясняющими, почему вам нужно или не нужно покупать золото. Все советы по инвестициям – случайный шум. Они включают мотивационные раздумья гуру, которые иногда зарабатывали деньги в прошлом.
Глава 7. Уравнение рекламы
Уравнение рекламы — математический способ автоматически выделять типы людей:
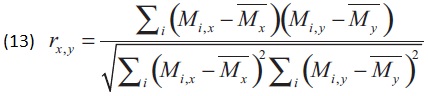
Здесь i относится к человеку, а х – к параметру. Mi,x – значение х для человека i. M̅x – среднее значение х для всех людей. Аналогично для параметра y. rx,y – парный коэффициент корреляции для параметров x и y.
Уравнение рекламы измеряет корреляцию между различными категориями. Например, если люди, которые обычно ставят лайк Кайли Дженнер, также ставят лайк и косметике, то коэффициент корреляции будет положительным числом. Но если люди, которые ставят лайки Кайли, и не ставят их Пьюдипаю, r будет отрицательным числом, и мы назовем это отрицательной корреляцией.
Как только платформа узнаёт, что привлекает определенного пользователя, она дает ему это в большом количестве. Большинство хотели бы, чтобы их уважали как личностей, а не изображали в виде каких-то стандартных типов. Уравнение (13) полностью игнорирует наши желания. Оно сводит нас к корреляциям между вещами, которые нам нравятся.
По мере того как наша жизнь все больше перемещается в интернет, доступные данные о нас также расширяются: с кем взаимодействуем в Facebook, что нам нравится, куда ходим, что покупаем — и список можно продолжать. Facebook, Google и Amazon сохраняют все социальные взаимодействия, все запросы и потребительские решения. Это мир больших данных. Нас теперь определяют не возраст, гендер или место рождения, а миллионы наблюдений, фиксирующих все наши действия и мысли.
У больших данных и корреляций есть одна проблема – они ничего не говорят о причинно-следственных связях! В начале эры больших данных предполагали, что корреляционные матрицы могут вести к лучшему пониманию пользователей и клиентов. Но все не так просто. Название книги Кэти О’Нил Оружие математического поражения хорошо отражает возникающие проблемы. Алгоритмы не избирательны. Термин «таргетированная реклама» подразумевает жесткий контроль над тем, кому она показывается, но на самом деле эти методы имеют очень ограниченные возможности по надлежащей классификации людей.
Для интернет-рекламы это невелика беда. Жизнь игрока в Fortnite не рухнет, если ему покажут рекламу косметики. Но совсем другое дело — если алгоритм назовет вас преступником, плохим учителем или террористом. Это может изменить карьеру и жизнь. Алгоритмы на базе корреляций изображались объективными, потому что основаны на данных. На деле же, как я обнаружил при написании своей книги В меньшинстве, многие алгоритмы делают почти столько же ошибок, сколько и точных прогнозов.
Глава 8. Уравнение вознаграждения
![]()
Здесь Qt+1 – накопленная оценка качества вознаграждения в момент времени t+1, Qt – качество вознаграждения в предыдущий момент времени t, Rt – размер вознаграждения в единицу времени, α определяет, насколько быстро я теряю уверенность при отсутствии вознаграждения (1–α)Qt или насколько вознаграждение повышает нашу оценку – αRt.
Каждое наблюдение приближает меня к истинному значению R. По этой причине Qt часто называют отслеживающей переменной: она отслеживает значение R.
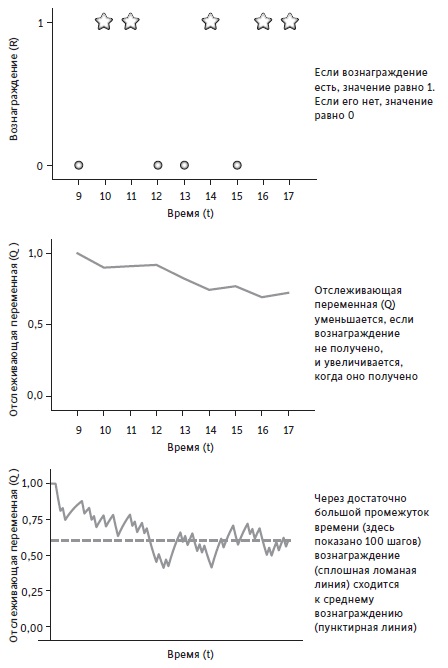
Рис. 11. Как отслеживающая переменная отслеживает вознаграждение
Подкрепление вознаграждения может раскручивать спираль обратной связи, и мы можем стать заложниками одного направления. Как найти баланс между следованием выбранной линией поведения, и исследованием нового? Ведь старый источник вознаграждения может истощиться. Это явление известно под названием «дилемма разведки/эксплуатации». Сколько времени тратить на использование уже известного, а сколько на изучение менее знакомых альтернативных вариантов?
Оказывается, решение дилеммы связано с другим понятием, которое обычно возникает в совершенно другом контексте: критическими точками – моментами, когда накапливается какая-то критическая масса и система резко переходит из одного состояния в другое. Например, мода внезапно распространяется после того, как авторитетные люди стали рекламировать бренд, или вспыхивает бунт, когда маленькая группа агитаторов заводит протестующих.
Лучший способ сбалансировать разведку и эксплуатацию – оставаться в состоянии, близком к критической точке. Если насекомые отойдут от нее, то слишком многие из них будут замкнуты на один источник пищи; они не смогут переключиться, когда появится что-то лучшее. Но если этому источнику будет привержено недостаточно насекомых и ситуация не дойдет до критической точки, то муравьи не смогут сосредоточиться на оптимальной пище. Они должны найти между разведкой и эксплуатацией золотую середину.
Глава 9. Уравнение обучения
В 2012 году YouTube плохо удерживал внимание пользователей, и владельцы YouTube обратились к специалистам Google. Проблема была в алгоритме и разработчики предложили воронку. Это приложение брало сотни миллионов видеороликов и сводило их примерно к десятку рекомендаций, представленных сбоку на странице сайта. Каждый пользователь получал собственную персонифицированную воронку с роликами, которые, возможно, он захочет посмотреть.
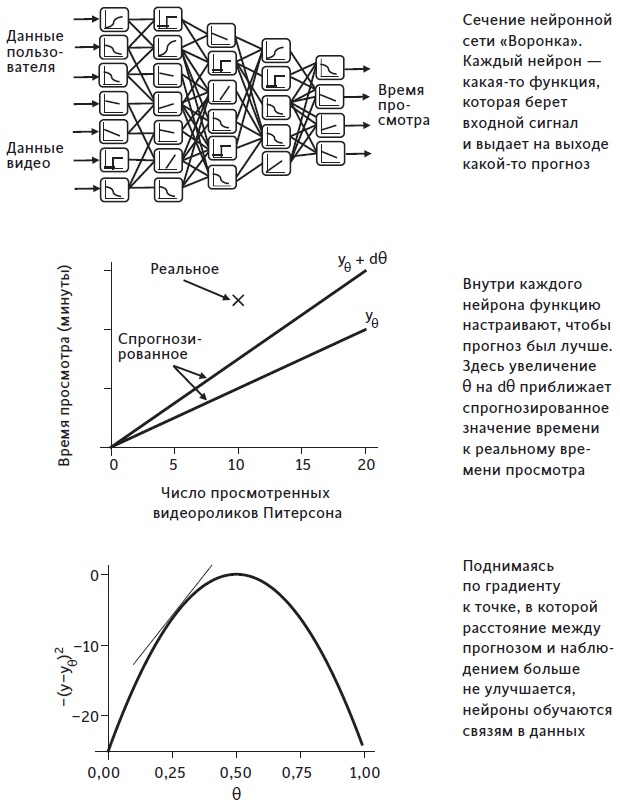
Рис. 12. Как обучается нейронная сеть
«Воронка» — нейронная сеть, которая изучает предпочтения при просмотре. Такие сети лучше всего представлять в виде столбца входных нейронов слева и выходных справа. Между ними находятся слои соединительных нейронов, известных как скрытые (рис. 12). Сеть не существует в физическом смысле: это компьютерные коды, которые моделируют взаимодействие нейронов. Однако аналогия с мозгом полезна, потому что именно прочность связей между нейронами позволяет их сетям изучать наши предпочтения.
Нейроны кодируют отношения в виде параметров — регулируемых величин, которые измеряют прочность отношений. В процессе написания книги я просмотрел несколько роликов Джордана Питерсона, и YouTube начал рекомендовать мне Бена Шапиро (оба автора придерживаются правых взглядов). Рассмотрим нейрон, отвечающий за определение того, сколько времени пользователи будут тратить на просмотр выступления Бена Шапиро. Внутри этого нейрона имеется параметр θ, который соотносит время, потраченное на видео Шапиро, с количеством просмотренных роликов с Джорданом Питерсоном.
Например, мы можем спрогнозировать, что количество минут, которое пользователь тратит на видео Шапиро (обозначим его yθ), равно θ, умноженному на количество просмотренных роликов Питерсона. Скажем, если θ = 0,2, то прогнозируется, что человек, просмотревший десять роликов Питерсона, потратит yθ = 0,2 * 10 = 2 минуты на видео Шапиро. Если θ = 2, то прогнозируется, что тот же человек потратит yθ = 2 * 10 = 20 минут на Шапиро, и т. д. Процесс обучения включает корректировку параметра θ для улучшения прогнозов для времени просмотра.
Именно это улучшение и использует уравнение обучения:
![]()
Это выражение говорит, что мы рассматриваем, как маленькое изменение dθ увеличивает или уменьшает квадрат расстояния (y – yθ)2. Математическая величина, задаваемая уравнением (15), известна как производная по θ или градиент . Она измеряет, приближает или отдаляет ли нас изменение θ от хорошего прогноза. Процесс медленной корректировки θ на основании производной часто называют градиентным подъемом. Следуя по градиенту, мы можем медленно улучшать точность искусственного нейрона (см. рис. 12).
Уравнение (15) – основа методов, известных как машинное обучение. «Воронка» берет видеоролики с самым большим прогнозируемым временем просмотра и ставит их в рекомендательные списки для пользователей. Если человек не выбрал новое видео, YouTube автоматически воспроизводит тот ролик, который, по его мнению, понравится пользователю больше всего. Успех «Воронки» был ошеломительным. В 2015 году время, потраченное на просмотр в YouTube пользователями возросло на 74%.
Если вы считаете, что ведете на YouTube разведку по своим интересам, а обнаруживаете, что смотрите предлагаемые видеоролики, то, к сожалению, заблуждаетесь. «Воронка» превратила YouTube в подобие телевидения, только программу составляет искусственный интеллект. И многие приклеиваются к этому экрану.
[1] Я собираю данные по элитным игрокам Fantasy Premier League и заметил, что доля элиты для разных стран сильно колеблется. А на первом месте норвежцы. – Здесь и далее прим. Багузина
[2] В Excel для перемножения матриц используется функция МУМНОЖ(). См. лист «Рис. 7» в приложенном Excel-файле. – Прим. Багузина
[3] Для этого примера стационарное распределение наступает на 11-й день.