Извлечение данных с web-страниц с помощью кода на языке Python
Если необходимые вам данные разбросаны по разным HTML-страницам для их извлечения применяется скрапинг. Вы создаете код для автоматического посещения определенного перечня страниц, получения конкретного контента с этих страниц и сохранения его в базе данных или в текстовом файле. [1]
Скажем, вы хотите скачать данные по температуре за прошедший год, но у вас не получается найти источник, который предоставил бы вам все сведения за нужный отрезок времени или по нужному городу. К счастью, сайт Weather Underground предоставляет исторические данные о погоде. И плохая новость: на одной странице сведения можно получить только за один день (рис. 1).
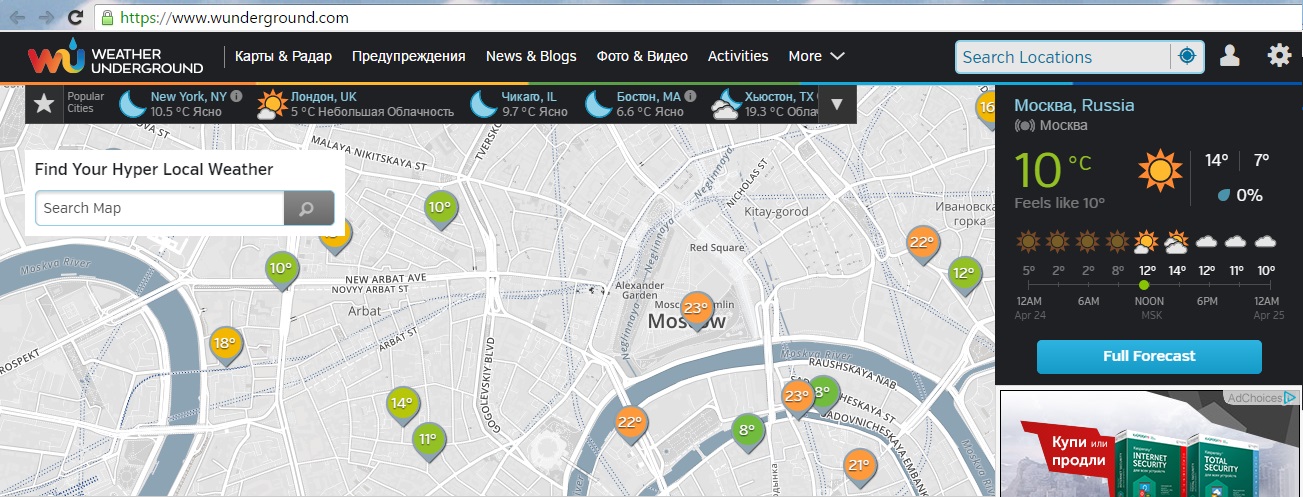
Рис. 1. Температура в Москве по данным Weather Underground; чтобы увеличить картинку, кликните на ней правой кнопкой мыши и выберите опцию Открыть картинку в новой вкладке
Подробнее »Извлечение данных с web-страниц с помощью кода на языке Python