Объяснение парадокса Монти Холла
Я преподаю магистрам курс «Статистическое мышление» и, объясняя термин пространство исходов, в качестве примера рассказываю о парадоксе Монти Холла. Напомню условия задачи в её классическом виде. Вы участник шоу, и вам показывают три одинаковые двери. За одной – авто, за двумя другими – козы. Монти Холл, ведущий шоу, просит вас выбрать одну из дверей. Вы делаете это, но не открываете выбранную дверь. Монти, который знает, где находится авто, открывает одну из двух других дверей. Он выбирает свою дверь в соответствии со следующими правилами:
- Монти всегда открывает дверь, за которой скрывается коза.
- Монти никогда не открывает дверь, которую вы выбрали изначально.
- Если Монти может открыть более одной двери, не нарушив первые два правила, то он выбирает свою дверь случайным образом.
После того, как Монти откроет свою дверь, он предлагает вам остаться с первоначальным выбором или переключиться на другую неоткрытую дверь. Что нужно сделать, чтобы максимизировать свои шансы на выигрыш автомобиля? Обоснуйте свой ответ прежде чем читать далее.
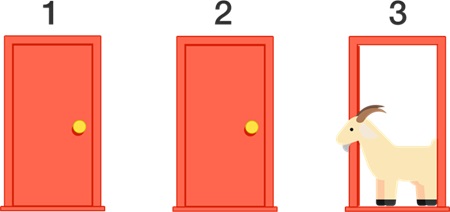
Рис. 1. Классические правила: после вашего выбора Монти Холл открывает одну из двух оставшихся дверей, за которой скрывается коза